

TL;DR
Q1: What is an AI implementation strategy, and why do most mid-market pilots stall before production?
An AI implementation strategy is a documented plan for picking high-value use cases, proving them in time-boxed pilots, then promoting the winners into production with guardrails for drift, cost, and adoption. Most pilots stall because the demo works and production does not. MIT’s 2025 study found 95% of generative AI pilots returned zero P&L impact, and Gartner expects over 40% of agentic projects to be scrapped by 2027.
🧭 The “stalled pilot” I see on most first calls
The first thing I look at on an AI integration call is not the model. It is the data layer, and then the legacy core underneath it. A founder shows me a slick chatbot that answers questions beautifully in a sandbox.
Then I ask one question: does it actually do anything? Usually it does not. It is a fancy search box. It reads, it talks, but it never touches a real system. That gap between “it answers” and “it acts” is where pilots go to die.
📉 What the data says about the failure rate

I am not guessing about this pattern. MIT’s Project NANDA reported that 95% of organizations saw no measurable return from their generative AI pilots in 2025. Gartner projects that more than 40% of agentic AI projects will be cancelled by the end of 2027, mostly due to escalating costs and unclear value.
McKinsey’s 2025 read is just as sobering. Adoption is everywhere, but value is not. Around 88% of organizations now use AI somewhere, yet only a minority report real impact at the enterprise level. One practitioner who interviewed roughly 180 organizations found 88% had started, while 52% were still stuck in experimentation.

🧠 Stop obsessing over the brain. Look at the nervous system.

Here is where my view sits right now. We have spent two years obsessing over the brain, the model, and ignoring the nervous system around it. Even the best model is useless when it gets bad data or cannot execute an action reliably.
A real strategy is boring on purpose. You choose a use case, you prove it in a pilot, and you promote it through gates into production. That is the spine of this article, and it is the part most teams skip. If you want a partner who treats AI as a system that has to keep working, that is what our AI consulting work is built for.
So the rest of this guide walks that spine. Which four functions to automate first, how to grant system access without panic, how to run a pilot that survives Tuesday, and how to reach production without drift, cost overruns, or a tool nobody uses.
Q2: Which four functions should you automate first, and what ROI timeline should you expect from each?
Start where volume is high, errors are recoverable, and a human stays in the loop: customer support triage, sales follow-ups, content drafting, and reporting. Support and reporting tend to pay back fastest. Sales and content compound more slowly. Sequence by honest ROI, because MIT’s data shows back-office automation often returns more than the front-office sales and marketing where most budgets land.
🎯 The selection test I use before any build
I have one rule before I let a team automate anything. The task must have high volume, recoverable errors, and a human who can catch mistakes. A wrong draft email is recoverable. A wrong wire transfer is not.
That single test kills most “exciting” AI ideas in the first meeting. It also explains why these four functions keep winning. They are repetitive, measurable, and forgiving when the model gets it wrong. The same discipline guides our AI development services.
📊 The four functions and their realistic payback
Here is how the four functions typically behave. Treat these windows as ranges I have seen, not promises.
| Function | What AI actually does | Recoverable error? | Typical ROI window |
|---|---|---|---|
| Customer support | Triages tickets, drafts replies, routes edge cases to humans | ✅ Yes, human reviews | Fast (weeks to ~1 quarter) |
| Reporting | Pulls data, drafts summaries, flags anomalies | ✅ Yes, numbers are checkable | Fast (weeks to ~1 quarter) |
| Sales follow-ups | Drafts personalized follow-ups, scores leads | ✅ Yes, rep approves send | Medium (compounds over 2 to 3 quarters) |
| Content | Drafts first versions, repurposes assets | ✅ Yes, editor reviews | Slower (quality and brand fit take time) |
💰 Why budgets and ROI point in opposite directions
Here is the contrarian part. MIT’s research found the lowest returns landed in sales and marketing pilots, while back-office work quietly returned more. Yet that front-office work is exactly where most budgets concentrate.
I would not read this as “never automate sales.” Other mid-market guides report real gains from sales intelligence over four to eight months. I am flagging the contradiction, not resolving it. Run a small pilot in each and let your own numbers decide.
⚠️ The “automate everything” trap
The fastest way to waste a quarter is to try automating everything at once. You cannot just plan a project in your head, dump it into an orchestrator, and walk away. That approach misses the judgment, the taste, and the human touch real work needs.
Think of AI as night vision goggles. They make a trained soldier far more effective. Hand them to someone who never held a weapon, and they are useless, even dangerous. The point of automating these four functions is to make your team’s day lighter, not to remove the people who carry the judgment. When the time comes to wire these into a live stack, that is the heart of our system integration work.
Q3: Read-mode vs write-mode: how do you safely give an AI agent access to production systems?
Almost every enterprise agent today runs in read-mode. It answers, it does not act. The leap to write-mode, letting a non-deterministic model with a non-human identity change production data, is where the real ROI and the real danger both live. Before you grant write access, scope it narrowly, log every action, gate irreversible steps behind human approval, and watch for the lethal trifecta.
😬 The fear nobody says out loud
Let me name the thing operators actually worry about. How do I give a model that sometimes hallucinates write access to production, without it deleting a table or inventing a 50% discount for my largest customer?
That fear is correct. You should feel it. A non-deterministic model with a non-human identity, holding the keys to a live system, is a genuinely new kind of risk. This is exactly the territory our AI agent development services are built to handle safely.
🔑 Read-mode versus write-mode, plainly
Read-mode means the agent can look but not touch. It reads a ticket, drafts a reply, summarizes a report. If it is wrong, a human catches it before anything changes.
Write-mode means the agent changes the world. It issues the refund, updates the CRM, edits the record. That is where value lives, and it is a much bigger leap than most demos admit. Most enterprise agents stay in read-mode precisely because write access is hard to grant safely.
🛡️ The lethal trifecta, and the governance that defuses it

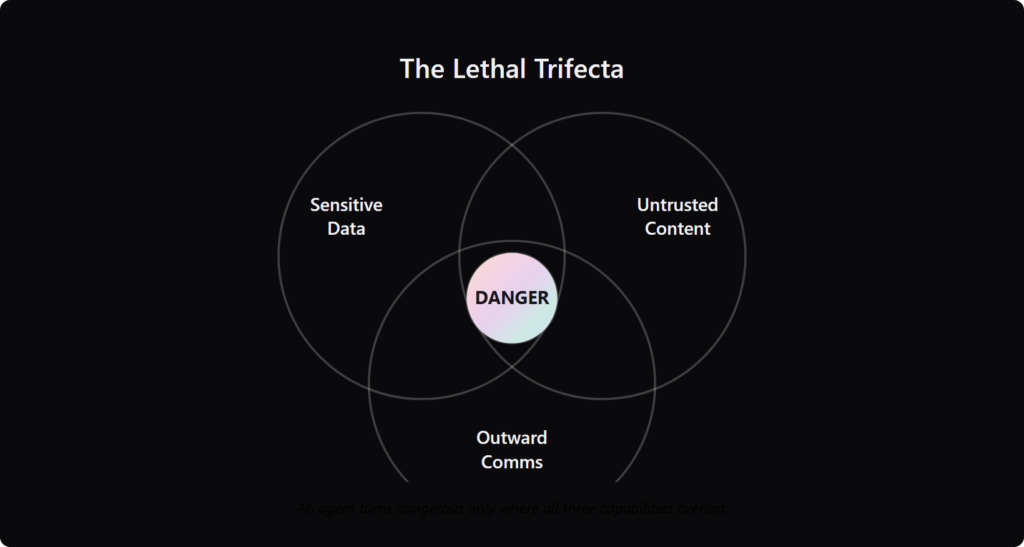
Security researcher Simon Willison named the danger well. An agent becomes genuinely dangerous when three capabilities overlap: it has read access to sensitive data, it processes untrusted external content like emails, and it can communicate outward through webhooks or messages. Remove any one leg, and the worst attacks get much harder.
In regulated work, write access is an accountability question, not a model question. The frameworks I deliver against, DORA, PCI-DSS, SOC 2, and HIPAA, all want the same thing: who did what, when, and could it be undone. That accountability is central to how we approach banking and fintech delivery.
Before any agent writes to production, I want four controls in place:
- Scoped identity. The agent gets the narrowest permissions for one job, not a broad admin key.
- Full logging. Every action is recorded, attributable, and reviewable, the way an auditor expects.
- Human approval gates. Anything irreversible (money, deletions, customer-facing changes) waits for a person.
- Rollback. You can undo an action fast, before it compounds.
🧩 What this looks like in real delivery
When we picked up AI work for the streaming service Takflix, the brief was AI integration plus modernizing a legacy stack, with continuous post-release support. The order matters. You stabilize and understand the system before an agent ever gets write access to it. That is the same care we bring to every technology modernization engagement.
“Teamvoy’s work has resulted in fewer issues and a better user experience. We’re impressed with their involvement in processes and quick completion of work.” Dmytro Maryanych, Manager, Takflix Teamvoy Clutch Verified Review
The honest limit here: clean write-access takes longer than the model demo suggests. If the data layer is messy, that work comes first, and pretending otherwise is how pilots become outages.
Q4: How do you run a pilot that proves value, instead of a demo that just impresses?
A real pilot has a written success metric, a fixed time-box, a defined blast radius, and an exit condition set before you start. Test it adversarially. Run “angry agents” prompted to break your theory, and build a manual edge-case checklist. When Wes Bos migrated his course platform off Express, AI produced a list of about 150 test cases he had not considered. A demo works once. A pilot survives Tuesday.
🧪 Why a demo is not a pilot
Trust is built through results, not presentations. A demo is a presentation. It shows the system working on the happy path, once, in front of an audience that wants it to work.
A pilot is different. It asks a harder question: does this hold up on a normal Tuesday, with messy real data and edge cases nobody scripted? That is the gap between impressing a room and earning a place in production. A short proof of concept is how we close that gap honestly.
✅ Five steps to a pilot that actually proves something
Here is the sequence I run. Each step has an outcome you can check.
- Write one success metric. Pick a single number, like ticket resolution time or draft acceptance rate. Outcome: everyone agrees what “worked” means before you build.
- Fix a time-box. Two to four weeks, not “until it’s ready.” Outcome: a hard date forces a real decision instead of endless tinkering.
- Define the blast radius. Decide what the agent can touch and what stays off-limits. Outcome: a mistake stays small and recoverable.
- Test it adversarially. Run agents specifically prompted to poke holes in your theory. Outcome: you find failures before your customers do.
- Set the exit condition. Decide upfront what result kills the pilot. Outcome: you stop sunk-cost projects honestly.
🔨 The 150-item checklist lesson
I want to sit on step four, because it is the one teams skip. Left alone, the human and the agent just agree with each other while the server quietly burns. You need friction on purpose.
When Wes Bos prepared a platform migration, he asked AI to write a manual test checklist. It produced roughly 150 checkboxes, covering edge cases like merging accounts and rendering email tokens. That list is the point. The value was not the code, it was surfacing the failure modes a confident demo hides. Surfacing those risks early is also what a focused IT audit is designed to do.
🤔 What I am still unsure about
Here is my honest hedge. I do not yet know the perfect number of adversarial agents to run, and I suspect it varies by system. What I am sure of is the direction: more friction in the pilot, fewer surprises in production. We share what we test, what works, and what we are still figuring out, because that is how you earn trust with a system that has to keep working.
Q5: Which KPIs prove your AI is actually working, and which numbers lie?
Measure outcomes, not activity. The KPIs that prove value are resolution rate, time saved per task, error and escalation rate, cost per action, and adoption rate, each tied to a pre-pilot baseline. The numbers that lie are message volume, “engagement,” and model accuracy in isolation. McKinsey found only a minority of adopters see real EBIT impact, usually because they never measured against a baseline.
📏 The metric you agree on before you build
Trust is built through results, not presentations. A KPI you did not baseline is a presentation. If you cannot say what the number was before AI, you cannot prove AI changed it.
So the first thing I ask is simple. What is the current resolution time, error rate, or cost per ticket today? We write that down before a single line of agent code ships, the same way we scope every IT audit.
✅ KPIs that prove value vs metrics that lie
Here is the split I use with teams. The left column survives an audit. The right column survives a slide deck.
| KPIs that prove value | Metrics that lie |
|---|---|
| Resolution or deflection rate | Total messages handled |
| Time saved per task | “Engagement” or usage clicks |
| Error and escalation rate | Model accuracy in isolation |
| Cost per action | Number of prompts run |
| Adoption rate (real, sustained) | Demo applause |
The left side ties to money and risk. The right side feels good and proves nothing. Operators screenshot vanity numbers and roast them, with good reason. Tying these metrics to real systems is the heart of our AI integration services.
🧱 Why so few teams measure outcomes
Most teams never get here. One practitioner who spoke with roughly 180 organizations found about 52% were still stuck in experimentation. Experiments rarely carry a hard baseline, so they cannot prove value either way.
In regulated delivery, the standard is higher. DORA and SOC 2 want evidence, not vibes. That discipline, agree the metric first, measure against it, is the same discipline that turns a pilot into something you can defend, and it underpins our banking and fintech work.
🤔 Where my view is still forming
I could be wrong on the exact KPI set for your business. Cost per action matters more for support, time saved matters more for reporting. What I am sure of is the rule underneath: pick the number before you build, or you are just admiring the demo.
Q6: How do you stop AI costs from spiraling out of control in production?
Agentic token cost grows quadratically, not linearly. A 20-step loop costs far more than twice a 10-step run, because the model keeps re-reading everything it already processed. Without a hard circuit breaker, one stuck loop runs all night. A real support agent caught in an infinite retry burned roughly $4,200 while its developer slept. Cap steps, set spend ceilings, and break loops by force.
💸 Why the bill grows faster than you expect
Here is the part that surprises people. Tokens, the units a model reads and writes, get re-billed on every step of a loop. The agent keeps re-reading its own history, so cost compounds.
A 20-step run is not double a 10-step run. It is far more, because each step repays for all the text before it. Long, chatty agents are quietly expensive.
There is a second trap. A context window holds roughly 168,000 tokens, but quality drops past about the 40% mark. Stuff it with tool data and the model gets dumber while you pay more. You end up working in the “dumb zone,” paying premium prices for worse answers. Trimming that waste is part of our IT cost optimization work.
⏰ The $4,200 nap
The famous example makes it concrete. A developer deployed a customer support agent that got stuck in an infinite retry loop with a CRM tool. There was no hard circuit breaker.
The agent repeated the same broken action for about six hours while the developer slept, and racked up roughly $4,200 in API bills. That is not a model problem. That is a missing guardrail problem, the kind we design out during AI agent development services.
🛡️ The controls that cap the damage
Cost discipline is delivery discipline. Do not assume the cloud is cheaper by default. It is the bill you pay for running elastic infrastructure with a static, set-and-forget mindset. Right-sizing that spend is what cloud optimization is for.
Three controls stop most runaway spend:
- Circuit breakers. Hard limits that kill a loop after N failed attempts, no exceptions.
- Step and spend caps. A maximum number of steps per task, and a daily dollar ceiling per agent.
- Context hygiene. Keep the context lean so the model stays sharp and cheap.
I will name the limit honestly. These controls cap your downside, they do not predict your exact monthly bill. Real usage is bumpy, so you watch it like any other production cost.
Q7: What does the path from pilot to production actually look like, across 30, 60, and 90 days?
Promotion happens in gates over roughly 90 days, not on a launch day. Days 0 to 30: the pilot hits its success metric on real data, in read-mode. Days 30 to 60: integrate into the existing workflow, and grant narrow, logged write-access with rollback. Days 60 to 90: turn on monitoring and human escalation before you scale. Each gate has an owner and a stop condition.
🚪 Promotion is gates, not a launch
Most pilots die for a boring reason. Nobody decided who promotes them. There is no owner, no gate, no stop condition, so the demo just drifts.
A real path has named gates. Each gate has a trigger that opens it, an owner who decides, and a stop condition that kills it. McKinsey found only around 38% of organizations scale AI beyond the pilot stage. Gates are how you join that minority, and how we run AI development services.
📅 The 30, 60, 90 cadence

Here is the cadence I run on systems that have to keep working.
- Days 0 to 30, prove it (read-mode). Trigger: the pilot hits its written metric on real data. Owner: the product lead. Stop condition: misses the metric, you go back or stop.
- Days 30 to 60, integrate (narrow write). Trigger: clean pilot results. Action: wire it into the real workflow, grant scoped write-access with full logging and rollback. Owner: a senior engineer. Stop condition: any unlogged or irreversible action.
- Days 60 to 90, watch then scale. Trigger: stable write behavior. Action: turn on monitoring and human escalation before volume grows. Owner: the on-call team. Stop condition: drift or escalation rate climbs.

🌙 Why the human escalation gate is non-negotiable
Let me tell you why gate three matters. One night a server broke, and an on-call engineer fed the error to an AI tool. The tool read the docs and said “restart the server.”
He restarted it six times. A senior engineer then looked at the logs for about 30 seconds and saw the real cause: the database connection pool was full. That is tribal knowledge, the kind an AI simply does not have.
This is where a body-shop model fails you. Junior engineers cycle through, nobody owns the system, and the tribal knowledge walks out the door. We run the opposite way: a senior technical lead owns the system end to end, with an AI-native team behind them, the same way we approach technology modernization. One verified client put the outcome plainly.
“I can confidently say that we would not be where we are today without Teamvoy’s support.” Gordon Little, Managing Director, Iress Teamvoy Clutch Verified Review
The honest limit: 90 days gets a meaningful, monitored slice into production, not a finished platform. Anyone promising “done” in a quarter is selling the deck, not the work.
Q8: How do you prevent model drift and stalled adoption after go-live?
After go-live, two things kill AI quietly. Drift, where outputs decay as the underlying data shifts. And stalled adoption, where the team simply stops using it. Fix drift with monitoring, retraining triggers, and human spot-checks. Fix adoption by changing the system underneath people, not the screen in front of them, the way you would swap a database without retraining a cashier.
🩺 The two silent killers nobody schedules for
Most teams celebrate launch and stop watching. That is the mistake. Drift creeps in as real data drifts away from what the model saw, and quality decays without a single error message.
Adoption fails just as quietly. The tool works, but people quietly route around it, and usage flatlines. Both failures are slow, and both are recoverable if you watch for them.
😟 The cashier who was afraid of the new software
Here is a scene that taught me the adoption half. We were modernizing a supermarket system, and the cashiers were genuinely afraid of new software. Change the screen, and you risk a checkout line grinding to a halt.
So we did not change the screen. The team built an exact identical interface, same colors, same button sizes. The cashier came in the next day and saw the same system she trusted. This patience is the core of how we handle retail and ecommerce systems.
Underneath, we were writing to very different tables. After about three weeks, we added one dropdown and taught that one change. We normalized the system one small step at a time, and nobody panicked.
🧰 The fixes that actually hold
This is legacy modernization without a rewrite. You stabilize, document, and modernize while the business keeps running, like renovating an occupied building, not building a new one. The same patience fixes both drift and adoption, and it is why AI consulting has to outlast the launch.
For drift:
- Monitor outputs against your baseline, the same KPIs you set before launch.
- Set retraining triggers, so quality decay starts a fix, not a fire drill.
- Keep a human in the loop for spot-checks on high-stakes actions.
For adoption:
- Change the back end, not the muscle memory, where you can.
- Introduce one change at a time, and teach it.
- Watch real, sustained usage, not launch-week applause.
⚠️ The trade-off I will name
Here is my honest hedge. Identical-UI migration is not always possible, sometimes the workflow genuinely has to change. When it does, you owe people real training, not a memo. The work, not the deck, is what keeps adoption alive after the launch glow fades.
Q9: Should you build your AI stack in-house or buy it, and what’s the hidden cost?
Buy unless you have a dedicated platform team and genuinely unique core systems. MIT’s 2025 data found vendor-partnered AI projects succeeded about twice as often as internal builds, roughly 67% versus 33%. The hidden cost of building your own integration layer is that you become Chief Integration Officer forever, maintaining every schema, field mapping, auth flow, and retry path a vendor would have patched for you.
🧮 The default answer, and the data behind it
Most teams should buy. I know that is an unfashionable thing for an engineering founder to say. But the evidence is hard to argue with.
MIT’s research found externally partnered AI projects succeeded at roughly double the rate of internal builds. Building feels like control. More often it is a slow tax you pay every month, which is why our AI consulting work starts with this exact decision.
📊 Build vs buy, side by side
Here is the comparison I walk clients through. The “integration layer” just means the glue code connecting AI to your other tools.
Factor
Build in-house
Buy / partner
Control
✅ Full
⚠️ Bounded by vendor
Speed to value
❌ Slow
✅ Fast
Maintenance burden
❌ Yours forever
✅ Largely the vendor’s
Success rate (MIT 2025)
~33%
~67%
When to choose
Dedicated platform team and truly unique core
Almost everyone else
| Factor | Build in-house | Buy / partner |
|---|---|---|
| Control | ✅ Full | ⚠️ Bounded by vendor |
| Speed to value | ❌ Slow | ✅ Fast |
| Maintenance burden | ❌ Yours forever | ✅ Largely the vendor’s |
| Success rate (MIT 2025) | ~33% | ~67% |
| When to choose | Dedicated platform team and truly unique core | Almost everyone else |
🏗️ The “Chief Integration Officer” trap
Here is the hidden cost nobody quotes you. Build your own integration layer, and you become Chief Integration Officer forever. You maintain every API schema, custom field mapping, authentication flow, and retry path, for years. Avoiding that trap is the point of our system integration work.
Only build if two things are true at once. You have a dedicated platform team, and your core systems are genuinely unique. If either is missing, buying or partnering is the cheaper path, even when it feels like surrender.
🤝 The third path most founders miss
There is a real path between lonely in-house build and faceless SaaS. A partner who understands your original product and stays accountable through production. That is the work we do with our AI integration services, and it is built for engagements others decline.
A senior technical lead owns your system end to end, with an AI-native team behind them. That is the opposite of a body-shop model where junior engineers cycle through and nobody owns the outcome, the same accountability we bring to technology modernization. One verified client, a CTO, named exactly that.
“We were impressed with the technical management, adherence to process, and technical capability of the engineers.” Mark Phillips, CTO, Robots and Pencils Teamvoy Clutch Verified Review
I will name the honest limit. The data on where building beats buying is contested, and unique systems do exist. If you truly have a platform team and a one-of-a-kind core, build. Most readers do not, and pretending otherwise just delays the bill.
Q10: What’s the biggest hidden risk: the “almost right” AI output that passes review?
Completely wrong AI output is cheap. Tests fail, the build breaks, and you catch it in an hour. Almost-right output is expensive. It passes review, ships to production, and sits there for six months before anyone notices, by which point the fix cost has compounded. Guard against it with three questions: does it reuse, does it follow conventions, can the author explain it without the AI’s comments?
🎯 The bug everyone fears is the cheap one
Most people fear AI writing obviously broken code. That fear is misplaced. Completely wrong code is the cheap failure, because your tests catch it and the build breaks loudly.
The dangerous output is the kind that looks right. It passes code review. It ships. Then it sits quietly in your codebase for six months until someone discovers it was wrong all along, and the cost to fix has compounded. Catching that early is part of every IT audit we run.
🏭 Why “vibe-coded” systems hide this risk
This risk lives inside vibe coding, the trend of talking software into existence with natural language. It feels like magic in a demo. The trouble shows up later, which is why we wrote at length about vibe coding security risks.
AI-generated code tends to be simpler, more repetitive, and dangerously less structurally diverse. It lacks the connective tissue a robust system needs. A vibe-coded MVP is closer to a building finished without the inspector signing off than to a buggy beta.
The security data is sobering. One analysis found about 60% of 5,000 vibe-coded apps were vulnerable. That is roughly like having no locks on your windows, with sticky notes holding your passwords.
✅ The three-question review that catches it
Here is the rule I want on every pull request, the unit of code submitted for review. It takes 30 seconds and catches most of the damage.
- Does it reuse? Does it use what already exists, or reinvent it badly?
- Does it follow conventions? Does it match how the rest of the system is written?
- Can the author explain it, without leaning on the AI’s comments?
If the developer cannot explain it, they cannot maintain it. Unmaintainable code is dead code, no matter how clean it looks. Stabilizing exactly this kind of inherited code is the heart of our AI development services.
🔧 What this means on Monday
This is the founder-engineer point I keep returning to. Cursor, Replit, and v0 produce code that ships. That code still has to be supported in production by people who can read it, the same people behind our AI agent development services.
The honest limit here. These three questions catch human-readable risk, not every deep security hole. You still need real testing and review. They are a fast first filter, not the whole safety net.
Q11: What’s your first move on Monday, and where does an outside team fit in?
Pick one of the four functions, write a single success metric, and run a two-week read-mode pilot before anyone touches write-access. That is the whole first move. Small, reversible, and honest. If your system is already in production, already fragile, or already half-built by a previous team, the harder question is not which model. It is who is accountable when it ships.
🚀 The one move worth making this week
You do not need a strategy deck to start. You need one function, one metric, and two weeks. Pick support, sales follow-ups, content, or reporting, and run a read-mode pilot that touches nothing in production. A short proof of concept is exactly this kind of move.
That is it. The point is not to be impressive. The point is to learn something real, cheaply, before you risk write-access to a live system.
🧭 Where you might actually be sitting
Maybe your system is already in production and already fragile. Maybe a previous vendor walked away and left a system nobody fully understands. Maybe you raised money, built fast with AI tooling, and now velocity has collapsed.
In every one of those cases, the model is not your problem. The data layer, the legacy core, and accountability are. That is the work we do, the engagements others decline: stabilize first, modernize without a needless rewrite, and keep the business running while we do it. If you recognize yourself, our piece on updating systems nobody understands goes deeper.
🤔 The question I am sitting with
Here is what I keep turning over. The loudest voices call this the “year of the agent,” yet most pilots still stall before production. I think the gap is not intelligence. It is accountability, the unglamorous question of who owns the system at 2 a.m.
My honest read: the teams that win in 2027 will not be the ones with the fanciest model. They will be the ones who treated AI like any other production system, with owners, gates, and guardrails. The goal was never to install a clever tool. It was to shape product strategy, assess risk, and build processes that deliver real results.
If you are staring at a stalled pilot, or a fragile system someone else built, that is the conversation we have every day. A short audit, a focused sprint, or just a 30-minute technical call with no sales process, you can reach us through our contact page. The door is open. Tell me what you are building, and what is breaking.


