

TL;DR
Q1. What is agentic AI implementation, and why do most pilots stall before production?
Agentic AI implementation is the engineering work of taking an autonomous, multi-step AI system from a demo into dependable production, where it plans, calls tools, and writes to live systems, not just reads them. Most pilots stall because the demo proved the model works. Production demands the architecture, integration, governance, and guardrails the organization never built. Gartner projects over 40% of agentic AI projects will be cancelled by the end of 2027.
🧩 The demo that worked, and then didn’t
I have watched this exact scene three times in the last year. A team shows a slick agent in a sandbox. Everyone claps. Then it has to touch a real CRM, and it stops.
The gap is not the model. The gap is everything around it. A demo answers questions; a production agent takes actions that cost money or break compliance.
That gap has a name in the field: the pilot-to-production cliff. You feel it the moment the agent needs write access to a system you cannot afford to corrupt.
🔍 Read-mode agents versus write-access agents
Here is the distinction that decides everything. An agent that only reads data is just a fancy search box. Production agents need write access to update CRMs, create tickets, and provision users.
Read mode is safe because nothing changes. Write mode is where the anxiety lives, because a non-deterministic model can now take a destructive action on a system you did not architect to absorb mistakes.
The numbers are blunt. One widely cited enterprise study found that 95% of generative AI pilots delivered no measurable return. Gartner adds that over 40% of agentic projects will be scrapped by 2027, citing escalating costs, weak risk controls, and unclear business value.
⚠️ Why the model is the wrong first question
The standard read gets this backwards. Teams obsess over the model, the brain, while ignoring the nervous system, which is integration. Even a top model is useless when it gets bad data or cannot execute actions reliably.
Across the AI integration calls I have taken over twelve years at Teamvoy, the first thing I look at is not the model. It is the data layer and the legacy core. Those two answers tell me whether a pilot can survive production, long before the model matters.
I could be wrong on any single project. The pattern, though, holds: the systems that cross the cliff are the ones that treated integration as the hard problem from day one.
🛠️ What actually surfaces (and where this article goes)
When you run agents for real, four things surface, and this article walks each one in order:
- Agent sprawl. Redundant and shadow agents that quietly burn budget.
- Legacy API gaps. Old systems that were never built for a tool-calling model.
- Prompt-injection exposure. A new attack surface that opens with write access.
- The pilot-to-production cliff. The governance and architecture work that turns a demo into a system.
Teamvoy works on the engagements where this matters most: regulated platforms in banking, insurance, and healthcare where downtime is a reportable event, not an inconvenience. We start with the data layer and the legacy core, then the model. That order is the whole point.
One honest limit before we go further. Not every workflow should become an agent, and I will name the ones that should not in the next section.
Q2. Which workflows should you hand to an agent first, and which to leave alone?
Start agents where genuine decisions are needed, use plain automation for repetitive deterministic tasks, and keep assistants for retrieval. The best first workflow has clear success criteria, a bounded blast radius, and tolerates a wrong answer without destroying data. If you have not delivered value with assistive copilots yet, you are not ready for autonomous agents with write access.
🎯 The flagship-workflow trap
The temptation is always the same. Pick the biggest, messiest, most expensive workflow and point the agent at it. That is how pilots die.
I steer first engagements toward a small, bounded workflow with a hard rollback instead. You want a place where a wrong answer is cheap to catch and cheap to undo. A flagship process is neither.
Here is the cost nobody prices in. Almost right is more expensive than completely wrong. Completely wrong gets caught, because tests fail and the build breaks. Almost right passes review, ships, and sits in production for six months before anyone notices the damage compounding.
🧭 Agents, automation, or assistants
Gartner’s own guidance is clean: use agents where decisions are needed, automation for repetitive tasks, and assistants for retrieval. Most “agent” projects are really one of the other two wearing a costume.
The table below is the rubric I use on a first scoping call, the same diagnostic lens behind our AI consulting work.
| Workflow type | Best fit | Why |
|---|---|---|
| Deterministic, rule-based, repetitive (data sync, formatting) | ⚙️ Automation | No judgment needed, so an agent adds cost and risk, not value |
| Lookup, summarize, answer from known sources | 🔍 Assistant | Read-only, so the blast radius is near zero |
| Multi-step, needs judgment, calls several tools, writes to systems | 🤖 Agent | Real decisions across steps, where autonomy earns its keep |
| Irreversible, high-stakes, no clean rollback (payments posting, prod migrations) | 🚫 Leave alone (for now) | “Almost right” here is catastrophic, not recoverable |
✅ The copilot-maturity gate
There is a sequencing rule worth holding. Master copilots before full autonomy. If assistive copilots have not yet produced value for your team, autonomous agents with write access are premature.
This matches what I see across Teamvoy delivery in regulated environments. The teams that succeed crawl before they run, scoping one agent to one task with one clear prompt. A focused agent is a correct agent.
One trade-off to name honestly. A bounded first workflow ships a meaningful milestone, not a finished platform. That is the point of starting small, and it is also its limit.
Q3. Why is your data layer, not the model, the thing that decides whether agents work?
Even the strongest model is useless on bad data or unreliable tool execution. The common failure is the “Dumb RAG” trap: dumping all your Confluence docs, Slack history, and Salesforce data into a vector database and hoping the model sorts it out. That floods the context and produces thrashing, not reasoning. Data readiness and retrieval design decide outcomes far more than which model you pick.
💸 The team that bought the best model and still got garbage
I have sat with teams who upgraded to the newest, most expensive model and saw their agent get worse. They assumed the model was the lever. It rarely is.
When AI lands on a stack with a messy data layer, it is closer to bolting a turbocharger onto an engine that already misfires than to a clean upgrade. More power into a broken system just breaks it faster.
🧠 The Dumb RAG trap, in plain terms
RAG means retrieval-augmented generation, where the agent pulls relevant data into its context before answering. The lazy version dumps everything in and prays.
Think of it this way. That approach dumps your entire hard drive into RAM and expects the processor to find one specific byte. You do not get reasoning. You get thrashing and context-flooding.
There is a hard threshold here. A large context window holds roughly 168,000 tokens, but around the 40% mark the model starts getting diminishing returns and effectively gets dumber as the context fills. Load it with sprawling tool definitions, JSON, and IDs, and you are doing all your work in the dumb zone.
🩺 What I check before anyone touches the model
The standard read obsesses over the brain and ignores the nervous system. The biggest, most overlooked bottleneck is integration: clean data in, reliable actions out.
Across 150+ projects at Teamvoy, many inside fintech, insurance, and healthcare where dirty legacy data is the default, our data-layer-first diagnostic looks at three things:
- Data quality and provenance. Is the source trustworthy, current, and access-controlled?
- Retrieval scoping. Does the agent pull the few right documents, or flood itself?
- Tool reliability. Do the actions the agent calls actually behave the same way every time?
Get those three right and a mid-tier model performs well. Get them wrong and no frontier model saves you. This is why solid data engineering precedes any model decision in our work.
One honest limit. Cleaning a legacy data layer takes longer than the model demo suggests, sometimes weeks, not days. I would rather tell you that on the first call than discover it in month three.
Q4. What does a production-grade agent architecture look like, from the five capabilities to the four control layers?
Agents run on five core capabilities: reasoning, synthesizing, generating, taking actions, and memory. Running them in production adds four control layers most pilots skip. An identity layer makes every action attributable. A tool-contract layer (MCP) constrains integrations. A data-boundary layer defines what the agent may touch. A runtime-detection layer catches behavioral drift. Demos skip all four because nothing is at stake.
🧱 The five capabilities, then the controls
Google’s framework names five capabilities an agent uses to operate: reasoning, synthesizing, generating, taking actions, and memory. That is the engine. It is necessary, and on its own it is not enough for production.
What turns capability into a system you can run is a control plane. The four layers below are the difference between a demo and software that can write to your CRM without becoming a liability, which is the heart of our AI agent development services.
🛡️ The four control layers
MCP (Model Context Protocol) is a standard way to expose your applications to an agent as defined, bounded tools. I think of it as solving “how do I API-fy production applications” safely, which is core to clean system integration.
| Control layer | What it does | What breaks without it |
|---|---|---|
| 🆔 Identity | Gives each agent a verifiable identity, so every action is attributable | Accountability collapses; no one can answer “which agent did this, and why” |
| 🔧 Tool contract (MCP) | Standardizes and constrains how the agent calls systems | Integrations sprawl; blast radius grows with every ad hoc connection |
| 🚧 Data boundary | Defines exactly what data the agent may read or write | Sensitive data leaks through grounding; the agent touches what it should not |
| 📡 Runtime detection | Watches live behavior and flags drift | Misbehavior goes unnoticed until it shows up in the bill or an incident |
These layers map onto recognized governance baselines, NIST AI RMF and ISO/IEC 42001, which research on agent governance grounds its frameworks in.

⚠️ Skip the cargo cult
One common mistake worth flagging. Sub-agents are for controlling context, not for anthropomorphizing roles. Do not build a “frontend agent,” a “backend agent,” and a “QA agent” because it feels organized. That is cargo-cult thinking. You fork a new context window to explore something specific, not to mimic a human org chart.
🏗️ Start with a minimum viable control plane
You do not need all four layers at full maturity on day one. You need the smallest version of each that makes the system auditable, then you scale it.
At Teamvoy, we build that minimum viable control plane first, auditable from the start, because in DORA, PCI-DSS, and SOC 2 environments, auditability is not a later phase. This is the same discipline we bring to technology modernization and surface early through an IT audit. The opposite approach, shipping the agent and bolting controls on afterward, is exactly how regulated pilots get blocked before launch.
The honest trade-off: a minimum viable control plane is a floor, not a finished governance program. It makes you safe enough to run one workflow well, which is precisely what you want before you scale to ten.
Q5. LangGraph vs CrewAI vs AutoGen vs Microsoft Agent Framework: how do you choose?
In 2026, LangGraph is the production standard for stateful, auditable workflows. CrewAI is the fastest path to a working multi-agent team. AutoGen suits research and experimentation. Microsoft Agent Framework fits Azure-committed enterprises that need governance built in. The right choice depends on whether you need traceability and state control, or speed to a first demo, not on benchmark hype.
🧰 The framework you cannot read at 2 AM is the wrong framework
Teams pick frameworks by what is trending on social media. That is backwards. The question is not which is most powerful. It is which one your team can still debug at 2 AM when an agent misbehaves in production.
A focused agent is a correct agent. The orchestration layer that enforces “one agent, one task, one clear prompt” beats the one with the most features. Scope discipline matters more than raw capability, which is the lens our AI agent development services apply on every build.
📊 The four frameworks, side by side
The framework-specific details below come from 2026 comparison sources, not from my own benchmarking.
| Framework | Orchestration style | Production-readiness | MCP support | Best for | Not for |
|---|---|---|---|---|---|
| LangGraph | Explicit, stateful graphs | High; the 2026 production standard, used by large firms | Yes | Stateful, auditable workflows | Teams wanting a fast demo with little setup |
| CrewAI | Role-based multi-agent crews | Medium to high | Yes | Fast path to a working multi-agent team | Deep state control and step-level auditing |
| AutoGen | Conversational multi-agent | Medium; research-leaning | Yes | Experimentation and research | Locked-down regulated production |
| Microsoft Agent Framework | Enterprise orchestration | High for Azure stacks; GA in 2026 | Yes | Azure-committed enterprises needing governance | Teams outside the Microsoft ecosystem |
🧭 Which one fits your situation
Map the choice to your real constraint, not the hype:
- You need every step audited (regulated fintech, insurance). LangGraph or Microsoft Agent Framework, because traceability is structural, not bolted on.
- You want a multi-agent prototype this month. CrewAI gets you moving fastest.
- You are exploring what is even possible. AutoGen is a fine lab.
- You live on Azure already. Microsoft Agent Framework reduces integration friction.
At Teamvoy, we stay framework-agnostic on purpose. I pick for the client’s constraints, their existing stack, their auditability needs, and whether their own team can support it after we hand off. The choice that looks clever in a demo and unmaintainable in year two is not a choice I will make for a system someone has to live with, which is why we treat AI integration as a long-term commitment.
⭐ What this looks like in delivery
This shows up in real engagements, not slideware. One client described our use of agentic AI across delivery this way:
“Teamvoy actively uses agentic AI across internal workflows and delivery, which speeds up development, raises quality, and adds extra value for the client.” Dmytro Maryanych, Manager, Takflix Teamvoy Clutch Verified Review
One honest limit. No framework saves a project on its own. The framework is maybe 10% of the outcome; your data layer, your tool contracts, and your guardrails are the other 90%.
Q6. What is agent sprawl, and how is it quietly draining your budget?
Agent sprawl is the uncontrolled spread of redundant, shadow, and orphaned agents across an organization. It is the new shadow IT. It shows up as duplicated functions, permission creep, and unmonitored delegation chains, and it bleeds money. Some companies rack up over $150,000 in unmonitored token spend in a single billing cycle, with zero business output. Only about 21% of enterprises have mature agent governance.
💸 The $150,000 nobody approved
Picture a finance lead opening a billing cycle and finding $150,000 in token spend with nothing to show for it. No owner. No output. Just agents nobody tracked, calling models on a loop.
This is the quiet crisis. Agents are cheap to spin up and easy to forget, so they multiply like unused servers did a decade ago. Reining that in is exactly what our IT cost optimization work targets.
🗂️ The shapes sprawl takes
Research on agent governance names a clear taxonomy. Sprawl is not one thing; it is five recurring patterns:
- Functional duplication. Three teams build the same agent, unaware of each other.
- Shadow agents. Agents nobody registered, running off someone’s personal key.
- Orphaned agents. The owner left; the agent keeps running.
- Permission creep. An agent slowly accrues access it never needed.
- Unmonitored delegation chains. Agents calling agents, with no one watching the chain.
There is a billing trap underneath this. Agent frameworks append every tool-call result and step to the history, then resend the whole cumulative log to the model each time. Your token use grows quadratically, not linearly. A 20-step loop is not twice a 10-step run; it is far more expensive.
⏰ The $4,200 nap
The sharpest version I know is the agent that took a nap and woke up to a bill. A developer deployed a support agent that got stuck in an infinite retry loop with a CRM tool. There was no hard circuit breaker, a safety stop that kills a runaway process.
It repeated the same broken action for six hours overnight, while the developer slept, and ran up around $4,200 in model charges. One loop. No output. Real money.
✅ Ownership is what kills sprawl
The fix is not clever tooling first. It is treating each agent as a product with a named owner, a lifecycle, and a kill switch, not a weekend experiment. Research shows organizations at higher governance maturity achieve dramatically lower sprawl, on the order of 94% lower sprawl indices, than the least mature.

A practical move I borrow from infrastructure work is the “scream test.” Temporarily isolate a suspected zombie agent for 48 to 72 hours and see who screams. If nobody does, it is dead weight you can retire.
At Teamvoy, an agent registry and clear ownership are part of how we keep delivery auditable, which matters when a regulator asks who authorized what, and it is one of the first things our IT audit services surface. The honest limit: a registry surfaces sprawl, it does not prevent it. Prevention is a governance habit, not a one-time cleanup.
Q7. Why do agents break against legacy APIs, and how do you bridge the gap without a rewrite?
Agents break against legacy systems because old APIs were built for deterministic, well-behaved callers, not for a model that retries, improvises, and floods endpoints. The fix is rarely a rewrite. You API-fy the legacy core behind an MCP tool contract, with strict rate limits, idempotency, and circuit breakers, so the agent gets bounded, auditable access without touching the system underneath.
⚠️ The endpoint that fell over
Here is a scene I have walked into more than once. A founder connects an agent to a legacy billing or CRM endpoint. It works in testing. Then the agent, retrying on a hiccup, hammers the endpoint until it falls over.
The legacy core was never built for this caller. It expected a careful client that calls once and handles errors. It got a model that improvises and repeats. Untangling that is the heart of recovering a legacy system nobody fully understands.
🔥 Why legacy plus non-determinism is combustible
The standard read blames the model. The real bottleneck is integration, the nervous system, not the brain. A capable model is useless if it cannot execute actions reliably against your systems.
Non-determinism means the agent does not behave identically every run. That is fine against a modern, resilient API. Against a brittle legacy endpoint with no circuit breaker, it is the $4,200 nap waiting to happen: a retry loop with no hard stop, draining money and stability while everyone sleeps.
🧱 The no-rewrite bridge
You do not rewrite the core. Legacy modernization is closer to renovating an occupied building than knocking it down. People still work inside while you make it safe, which is the principle behind our technology modernization work.
The bridge is a tool contract. MCP (Model Context Protocol) lets you expose the legacy system to the agent as defined, bounded tools, which is really about safely API-fying production applications through clean system integration. You wrap the core, you do not replace it. The wrapper enforces:
- Rate limits. The agent cannot flood the endpoint.
- Idempotency. Idempotency means a repeated call has no extra effect, so retries stop being dangerous.
- Circuit breakers. A hard stop kills a runaway loop before it bills you for six hours.
- Audit logging. Every action against the legacy core is recorded.
Industry research backs the priority: over 90% of enterprises plan to integrate agents with existing systems within three years, and integration is repeatedly named as a top deployment hurdle.
🏗️ When the rewrite actually is the answer
I will not pretend wrapping always wins. There is an “it depends” worth stating plainly. If a data-center lease expires in under 60 days, defaulting to a careful refactor mid-flight guarantees broken services and a missed deadline; a rehost first is the safer call.
Across 150+ projects at Teamvoy, many in banking, insurance, and manufacturing, the rescue-not-rewrite pattern fits most cases, but not all. Sometimes the honest answer is a staged rebuild, and I would rather say so on the first call than discover it in month six. The wrapper buys you time and safety; it is not always the final destination.
Q8. How do you build trust into agents: securing against prompt injection while keeping humans in the loop and decisions traceable?
Trust equals traceability plus fallbacks. An agent turns dangerous at the “lethal trifecta”: access to sensitive data, exposure to untrusted external content, and an external communication channel. That is exactly what prompt injection exploits. Defend with least privilege, human-in-the-loop approval on consequential actions, output validation, and full decision logging, so every action is reconstructable when a regulator or a 2 AM on-call engineer asks why.
🤖 The agent that clicked “I’m not a robot”
Two scenes frame the risk. In the first, an engineer watches an agent happily click an “I’m not a robot” button and walk straight past bot protection to scrape the data behind it. The agent did what it was told, and what it was told was dangerous.
In the second, a 2 AM incident, an on-call engineer fed an alert to an AI tool. It read the docs and said “restart the server,” so he restarted it six times before escalating. A senior engineer read the logs for 30 seconds and saw the real cause: a database connection pool full because of a batch cron job. That is tribal knowledge the tool never had.
🎯 The lethal trifecta, and what to do about it
Prompt injection means malicious instructions hidden in content the agent reads, like an email or a web page, that hijack its behavior. It need not be human-readable to work; if the model parses it, it can be attacked. The risk peaks at the intersection of three capabilities.
The controls below map to the OWASP Top 10 for LLM applications, the recognized security baseline, and reflect how we build AI autonomous agents for regulated environments.
| Risk | Real example | Control |
|---|---|---|
| 🔓 Prompt injection (OWASP LLM01) | Hidden instructions in a scraped page redirect the agent | Treat all external content as untrusted; validate inputs and outputs |
| ⚡ Excessive agency | Agent provisions users or sends emails it should not | Least privilege; human-in-the-loop on consequential actions |
| 📤 The lethal trifecta | Sensitive data, untrusted input, and an external channel meet | Sever one leg; remove the external channel or restrict data access |
| 🕳️ Tribal-knowledge gaps | “Restart the server” six times, wrong fix | Encode runbooks; require log review before destructive actions |
The cheapest defense is severing one leg of the trifecta. An agent that cannot send emails or trigger webhooks is far less dangerous, even if the other two legs remain.
🧾 Trust is traceability plus fallbacks
Trust is not a feeling; it is structure. Log the prompt, the tools called, the inputs, and the reasoning path, so any action can be reconstructed later. Auditability and clear reasoning pathways matter as much as output quality.
A habit I rely on is the “angry agent.” That is an agent specifically prompted to poke holes in the plan, because otherwise the human and the agent just agree with each other while the server burns. Adversarial review beats mutual reassurance.
🛡️ What auditable delivery looks like
At Teamvoy, guardrails and audit trails are built in from day one, not bolted on at the end, because in DORA, PCI-DSS, and HIPAA environments, “we will add logging later” is how a launch gets blocked. This is the same posture behind building regulator-ready AI in fintech. Trust is built through results, not presentations.
One honest limit. No control set makes an agent perfectly safe. The goal is a bounded blast radius and a clear record, so when something goes wrong, and at some point it will, you can see exactly what happened and roll it back.
Q9. What ROI can you realistically expect, and how do you avoid the 95% that returns nothing?
ROI on agentic AI is real, but unevenly distributed. Leaders report strong returns, while laggards sit below break-even. One widely cited enterprise study found 95% of generative AI pilots returned no measurable value. Sustainable ROI comes from redesigning whole workflows and compressing time-to-production, not from automating isolated tasks. The single biggest lever is moving from pilot to production fast, with governance built in.
💸 The 95% nobody wants to be in
Start with the uncomfortable number. Across enterprise generative AI pilots, 95% failed to deliver a single dollar of measurable return. That is not a model problem. It is a deployment and value problem.
The money is real and finite. Token spend, engineering time, and opportunity cost all come out of a budget that could have gone to something that shipped, which is why disciplined IT cost optimization matters before a single agent goes live.
📊 ROI is a spread, not a single number
Here is what the category gets wrong. People quote one hero ROI figure. The honest picture is a wide spread between mature adopters and everyone else.
The numbers below come from different studies with different methods, so treat them as a range, not a verdict. I am flagging the contradiction on purpose, because the sources do not fully agree.
| Cohort | Reported outcome | Source note |
|---|---|---|
| Enterprise pilots overall | 95% returned zero measurable value | Broad pilot sample |
| Early agentic adopters | High ROI rates and meaningful efficiency gains reported | Self-reported, leaning optimistic |
| Scaling organizations | Roughly 23% scaling an agentic system in 2025 | Adoption, not profit |
| Laggards | Returns near or below break-even | Methodology varies by study |
The contradiction is the point. When one study says “zero return” and another says “strong ROI,” they are usually measuring different cohorts at different maturity. Do not let a vendor quote you only the top of that range; an independent IT audit grounds the number in your reality.
⏰ Time-to-production is the real lever
The standard read chases the model. The lever that actually moves ROI is time-to-production. Compressing idea to pilot to production to scale is where measurable value comes from, which is the thinking behind our AI modernization sprints.
The other half is workflow redesign. Sustainable ROI comes from rethinking entire workflows, not bolting an agent onto one isolated task and hoping. Automating a broken process just makes the breakage faster, so sound AI integration starts with the workflow, not the model.
A sobering aside on the cost of getting it wrong: one estimate suggests it would take 61 billion work-days to pay off the world’s current technical debt. Agents built carelessly add to that pile, which is why we wrote about the tech debt avalanche.
✅ How we think about it
At Teamvoy, we work to compress time-to-production because that is where the return lives, and we say plainly when an agent is the wrong tool. Sometimes the honest answer is automation, or an assistant, not an agent at all, and our AI consulting begins there.
The trade-off worth naming: a fast first milestone is not a finished platform. A 2-week Sharp Sprint ships a meaningful, working slice, enough to prove value or kill the idea cheaply, not the whole system. Killing a bad idea in two weeks is itself a strong return.
Q10. How do you take a stalled pilot across the production cliff, your sequenced path?
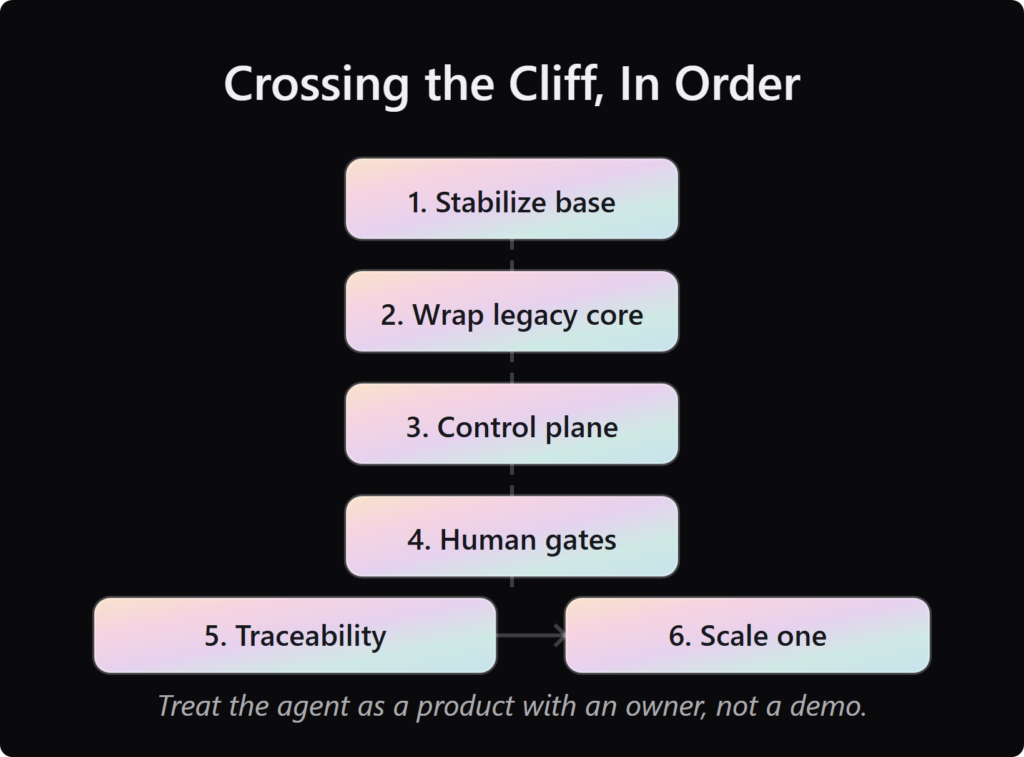
Crossing the cliff is sequenced, not heroic. Stabilize the pilot’s data and tool reliability, wrap the legacy core behind a tool contract, install the four-layer control plane and human-in-the-loop gates, instrument full traceability, then scale one workflow at a time with cost and incident metrics in view. Treat the agent as a product with an owner, not a demo you keep restarting.
⚠️ The cost of leaving it stalled
A stalled pilot is not neutral. It quietly costs you. Sprawl grows, token spend leaks, and risk compounds while everyone waits for someone to own it.
I have been shipping production systems for over a decade, and this is a new pattern that is now everywhere. The demo is easy. The crossing is the work.
A useful way to think about tooling: night-vision goggles do not give you more soldiers, they make trained soldiers more effective. Goggles on someone who never held a weapon are useless and dangerous. Agent tooling on a team without production fundamentals is the same, a point we make about vibe coding security risks.
🪜 The sequenced path across
You cross the cliff in order, not all at once. Each step earns the next:
- Stabilize the foundation. Fix data quality and tool reliability first, because a shaky base sinks everything above it.
- Wrap the legacy core. Put a tool contract, with rate limits and circuit breakers, between the agent and your old systems.
- Install the control plane. Add identity, the tool contract, a data boundary, and runtime detection, even in minimum viable form.
- Add human-in-the-loop gates. Require approval on consequential, irreversible actions.
- Instrument traceability. Log the prompt, the tools, the inputs, and the reasoning path, so every action is reconstructable.
- Scale one workflow at a time. Watch cost and incident metrics, and expand only when the last one holds.
This is rescue, not rewrite. Legacy modernization is closer to renovating an occupied building than knocking it down. The business keeps running while you make it safe, the core promise of our technology modernization work.
🛠️ Where Teamvoy fits
This is the work we do at Teamvoy: the engagements others decline, where the system is regulated, live, or already broken. A senior technical lead takes ownership end to end, backed by an AI-native team, across an average engagement of four years or more. Whether you are a CTO who inherited a broken system, a founder whose AI-built MVP is hitting limits, or an IT director facing a compliance deadline, the entry point is the same: show us what is breaking, and our case studies show how that has played out.
🔭 The question I am sitting with
Here is where my view sits right now. The teams that win the next two years will not be the ones with the best model. They will be the ones who treated agents as production systems from day one, with owners, controls, and a record, which is exactly how we approach AI agent development.
So the question I would put to you is simple. If your agent took a destructive action tonight while everyone slept, could you see exactly what it did and roll it back by morning? If the answer is no, that is the conversation worth having.


