
Q1. What is an enterprise AI strategy, and why does diagnosis come before the goal? [toc=1. What It Is]
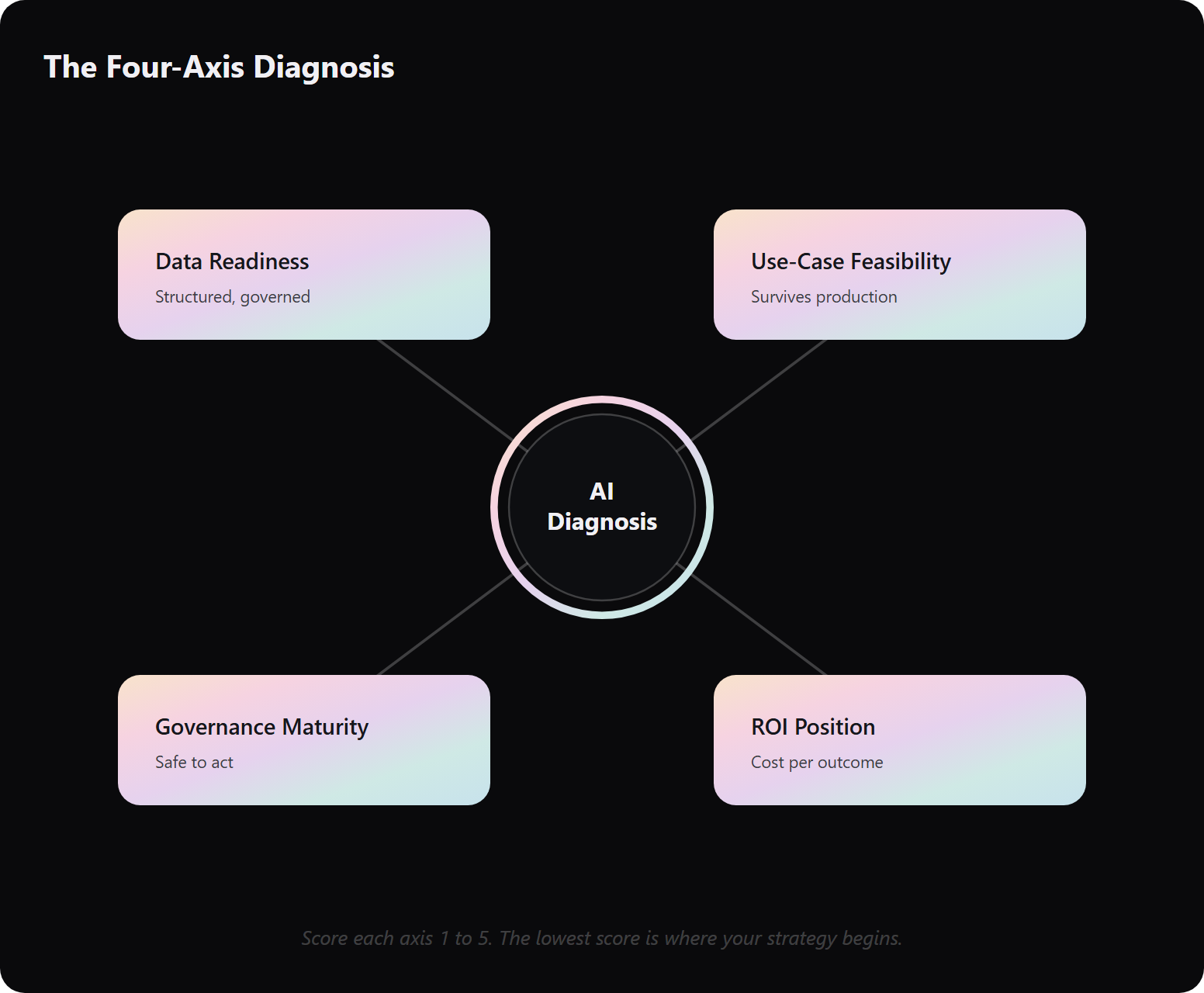
An enterprise AI strategy is a decision system that locates where your organization actually stands on four axes, data readiness, use-case feasibility, model and governance maturity, and ROI position, before it sets any objective. Its core components are data, use cases, governance, and economics. Most strategies fail because they start with a goal (“deploy agents this quarter”) instead of an honest diagnosis. You cannot set a credible target from a position you have not measured.
🧭 The board asked for a number, and the room went quiet
I have sat in that room. A board wants an “AI roadmap” by next quarter, and the Head of AI has three stalled pilots and a token bill nobody wants to explain. The instinct is to set a bold goal fast. That instinct is the problem.
The first thing I look at on an AI integration call is not the model. It is the data layer, then the legacy core. The model is the last question, not the first. One sharp framing I keep coming back to: we have been obsessing over the brain while ignoring the nervous system. Even a top-tier model is useless when it gets bad data or cannot execute actions reliably.
📊 Diagnosis-first beats goal-first, and the data says so
The numbers back this up. MIT’s Project NANDA found that roughly 95% of enterprise generative AI pilots delivered no measurable profit-and-loss impact. McKinsey’s 2025 survey found that while 88% of organizations use AI in some function, only about a third have scaled it past experiments.
Read those two together. Adoption is near-universal. Results are rare. The gap is not ambition. It is that most teams set a goal before they knew their own starting position. From what surfaces when you actually run these engagements, the firms that scale are the ones that measured first.
✅ The four axes you score before you set a target
Here is the frame the rest of this article runs on. Score yourself honestly on each before you commit to anything:
- Data readiness ⭐: is your data accessible, governed, and structured enough for a model to reason over.
- Use-case feasibility: will the use case survive production, not just a demo.
- Model and governance maturity: can you let a model act safely, with controls you can audit.
- ROI position 💰: do you know your cost per outcome, not just your spend.
At Teamvoy, every engagement I have led across 150+ delivered projects starts here, with a diagnosis, not a transformation pitch. Twelve years in regulated industries taught me one thing plainly. A goal set on top of an unmeasured stack is a guess wearing a deadline. This is the discipline behind our AI consulting work.
Your Monday action is small and uncomfortable. Score the four axes from 1 to 5, before you write a single objective. The lowest score is where your strategy actually begins.
Q2. Why do 95% of enterprise AI pilots stall, is your infrastructure broken or your execution? [toc=2. Why Pilots Stall]
Pilots stall for two distinct reasons that get blamed on each other. MIT’s NANDA study points to a learning and workflow gap, tools that never integrate into how work actually happens. Gartner and Deloitte point to data readiness and governance gaps. Both are real. Your job is to diagnose which one is blocking you, because the fix for a workflow gap is not the fix for a broken data layer.
🤔 The question every CTO is actually asking
Behind the polite roadmap conversation, the real question is quieter. “Is my infrastructure fundamentally broken for AI, or do I just need better prompts?” I have shipped production systems for a long time, and I will say it plainly. This is a new failure pattern, and it is everywhere right now.
The standard read gets this backwards. People assume one root cause. There are two, and they need opposite fixes.
🧠 The first story: it is a workflow gap
MIT’s Project NANDA framed the 95% failure rate as a learning and workflow problem. The tools work in a demo. They never get woven into how a team actually does the job. The pilot becomes a parallel toy, not a part of the workday.
I see this constantly. A team buys a clever tool, runs a flashy proof of concept, then nobody changes their actual process. The tool sits unused. That is not a broken server. That is a broken adoption path.
🗄️ The second story: it is a data and governance gap
Then there is the other camp. Gartner projected that more than 40% of agentic AI projects will be cancelled by the end of 2027, citing rising costs, unclear business value, and weak risk controls. Deloitte’s work on AI readiness puts data quality, governance maturity, and infrastructure as the things to assess before you deploy anything.
These two stories contradict each other, and I am not going to pretend they resolve neatly. MIT says the problem is rarely infrastructure. Gartner and Deloitte say infrastructure and governance are exactly where projects die. I think both are true, in different shops, which is why a generic “AI transformation” pitch helps neither.
A concrete tell of the execution-gap version: teams dump every Confluence doc, Slack thread, and Salesforce record into a vector database and hope the model figures it out. You do not get reasoning. You get thrashing and context-flooding. And the most expensive failure mode is code that is almost right. It passes review, ships, and sits wrong in your codebase for six months before anyone notices.
🔍 A two-line test to find your gap
Run this on Monday. First: pick your most-used pilot and ask, “did anyone change their daily workflow to use it.” If no, your gap is workflow. Second: ask your data team, “can we retrieve one specific fact for one customer, cleanly, in under a minute.” If no, your gap is data.
This is the work we do at Teamvoy before proposing anything, name which gap you actually have. An independent IT audit often surfaces it fast. The fix you fund should match the gap you found, not the one a vendor deck assumed.
Q3. How do you diagnose your data readiness for AI? [toc=3. Data Readiness]
Data readiness is not how much data you have. It is whether the data is accessible, governed, and structured enough for a model to reason over it. Diagnose it across four checks: data quality and lineage, access and permissions, structure (can a model retrieve one fact without context-flooding), and a “scream test” for zombie data. Loading your whole hard drive into a vector database is not readiness. It is thrashing.
📦 “We have tons of data” is a trap, not a head start
The most confident sentence I hear on a readiness call is “we have all the data we need.” It is usually wrong. Volume is not readiness. A warehouse full of unlabeled, duplicated, half-owned data is a liability the moment a model tries to use it.
By the end of this section, you will be able to run four concrete checks and walk away with a 1-to-5 readiness score. These map to the dimensions analysts like TDWI use in their data governance and AI-readiness models, quality, access, structure, and lifecycle. Getting these right is the foundation of any serious data engineering effort.
✅ The four readiness checks, and what each should tell you
Run each check and note the expected outcome:
- Quality and lineage ⭐: can you trace where a field came from and trust it. Expected outcome: you can name the source system and last-validated date for your top 20 fields.
- Access and permissions: can the right system reach the right data, with the wrong access blocked. Expected outcome: a clear map of who and what can read each dataset.
- Structure: can a model retrieve one fact without dragging in noise. Expected outcome: a single query returns one clean answer, not a flood.
- Lifecycle (the scream test) ⚠️: do you know which data is still alive. Expected outcome: a list of suspected dead, or “zombie,” datasets to test.
🧪 Why structure matters more than people expect
Here is the part most strategies skip. Models have a working-memory limit. Push past roughly 40% of the context window and quality drops, the model effectively gets dumber as the context fills with junk. If your retrieval dumps raw JSON and IDs into that window, you are doing the real work in the dumb zone.
This is why the “dump everything into a vector database” pattern fails. It is like dumping your entire hard drive into RAM and asking the CPU to find one byte. You get context-flooding, not answers. Structure is what lets a model find the one fact that matters.
🔇 The scream test for zombie data
My favorite tactical move costs almost nothing. Temporarily isolate a suspected dead dataset at the network level for 48 to 72 hours. Then watch who screams.
That window reveals hidden dependencies standard monitoring misses, a monthly batch job, a quarterly audit export, a report nobody documented. At Teamvoy, on the modernization engagements I have led, the data layer is question one and the legacy core is question two. The model is always last. Trust me, the boring data work is where AI projects are quietly won or lost.
Q4. How do you score AI use-case feasibility instead of chasing the demo? [toc=4. Use-Case Feasibility]
Use-case feasibility is whether a use case survives production, not whether it dazzles in a demo. Score each candidate on business impact, data availability, integration cost, and supportability, can your team read, maintain, and explain the system afterward. A demo that “feels like magic” but produces code nobody understands is not feasible. It is debt with a deadline.
🎩 The demo was magic, so why is nothing shipping
I have watched a brilliant demo win a budget, then watched the same project stall for a year. The demo is designed to impress. Production is designed to break you. The board sees the magic and asks, six months later, why nothing has shipped.
The honest answer is usually that the use case was never feasible. It was just photogenic. Here is the rubric I use to score candidates before anyone commits.
📋 The feasibility scoring matrix
Score each use case 1 to 5 on four criteria. Add them. Anything under 12 needs a hard second look.
| Criterion | What a high score looks like | Not feasible for you if |
|---|---|---|
| Business impact 💰 | Tied to a real metric, revenue or cost | Nobody can name the metric it moves |
| Data availability | The data exists, clean and reachable | You would have to build the data first |
| Integration cost | Plugs into existing systems cleanly | It needs a custom integration layer per system |
| Supportability ✅ | Your team can read and maintain it | Only the original AI prompt “understands” it |
That last row is the one most strategies ignore, and it is the one I weigh hardest.
🏗️ Vibe coding is a technical-debt factory
There is a trend where developers describe software in natural language and let AI “vibe” it into existence. It feels like magic in the demo. The trouble is that AI-generated code tends to be simpler, more repetitive, and dangerously less structurally diverse. It lacks the connective tissue a system needs to stay robust.
The receipts are ugly. One analysis found a 4x surge in code cloning, where AI copies similar blocks instead of building reusable logic. A security review of 5,000 vibe-coded apps found 60% were vulnerable, the digital equivalent of no locks on the windows. Code that ships still has to be supported in production by people who can read it, which is exactly why vibe coding security risks compound so fast.
❓ The three-question gate before you greenlight
Before any AI-built feature goes to production, we run a simple review on the pull request:
- Does it reuse what already exists, or reinvent it.
- Does it follow your conventions.
- Can the developer explain it without reading the AI’s comments.
If the answer to the third is no, the code is unmaintainable, and unmaintainable code is already dead. At Teamvoy, supportability is a feasibility criterion, not an afterthought, because we are often the team called in for AI development when an AI-built MVP hits its limit. One client put the payoff plainly after we integrated AI and modernized their legacy stack:
“Teamvoy’s work has resulted in fewer issues and a better user experience… we’re impressed with their involvement in processes and quick completion of work.”
Dmytro Maryanych, Manager, Takflix Teamvoy Clutch Verified Review
Feasibility, in the end, is just honesty about what your team can carry after the demo applause stops.
Q5. What does model and governance maturity look like, and why is “write access” the real line? [toc=5. Governance Maturity]
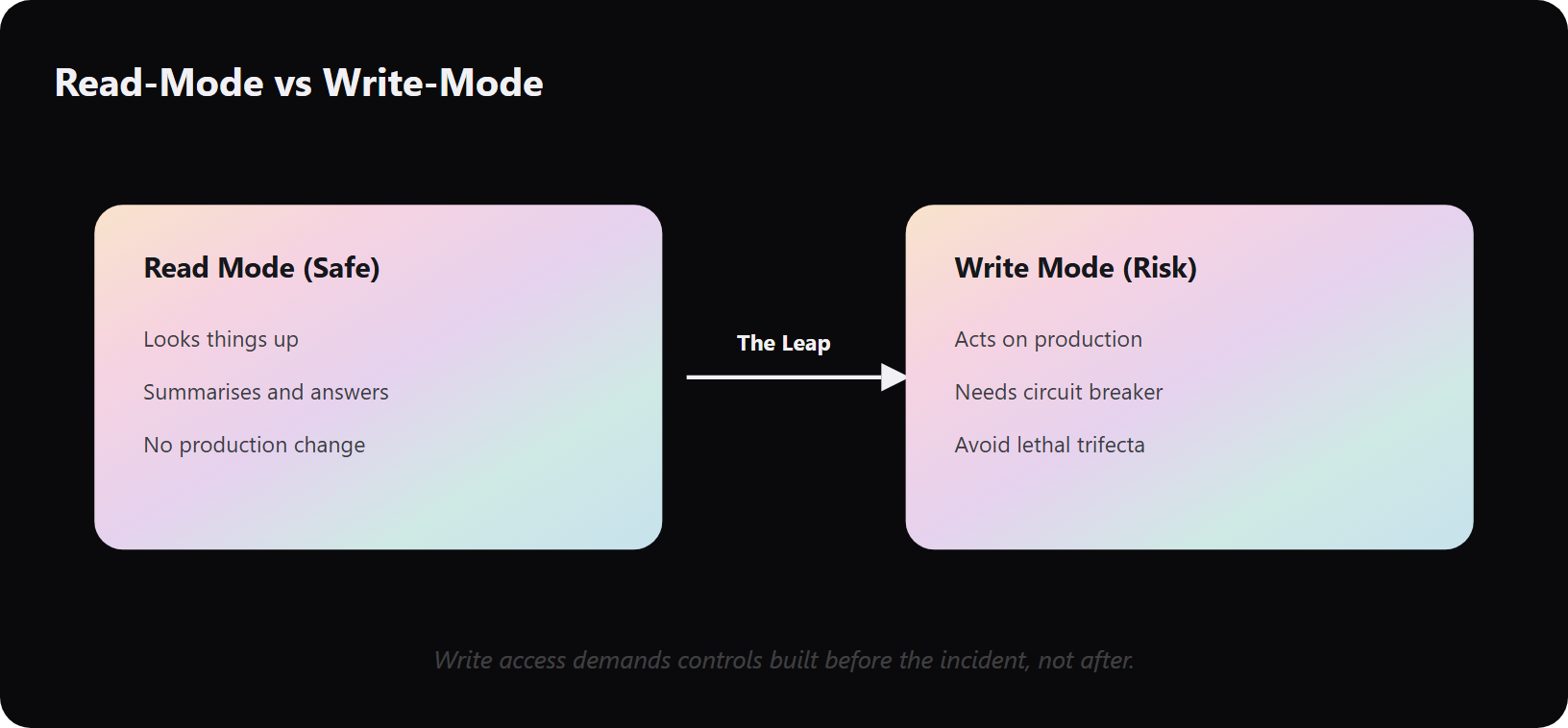
Governance maturity is your ability to safely let a non-deterministic model act, not just answer. Benchmark it against NIST AI RMF (Govern, Map, Measure, Manage) and ISO/IEC 42001. The real maturity line is read-mode versus write-mode. Almost every enterprise agent today only reads. Giving a non-deterministic, non-human identity write access to a production system is the leap, and it demands controls most organizations have not built.
🔐 The 2 AM fear nobody says out loud
Here is the thing that keeps a careful CTO up at night. A model with write access can change a production record, send a payment, or email a customer. It is non-deterministic, meaning it can give a different answer to the same question twice. You are handing the keys to something that does not reason like a person.
I have delivered into regulated environments for years, BaFin, PSD2, DORA, HIPAA, GDPR. In those worlds, downtime is a reportable event, not an inconvenience. So I will state the governing thought plainly. Maturity is not which model you picked. It is whether you can let that model act and still sleep, which is the heart of building regulator-ready AI in fintech.
📐 Pillar one: benchmark against named frameworks
Do not invent your governance from scratch. Two named, dated standards already exist:
- NIST AI Risk Management Framework ✅: organized around four functions, Govern, Map, Measure, and Manage, with a generative-AI profile added in 2024.
- ISO/IEC 42001: a certifiable AI management-system standard you can audit against.
Score yourself against these. If you cannot say which NIST function your controls cover, that is your maturity gap, in writing. A structured IT audit is the fastest way to surface it.
⚠️ Pillar two: read-mode is safe, write-mode is the leap
Almost every enterprise agent today is in read mode. It looks things up. It summarizes. It answers. Getting to write access, where the agent changes the system, is a genuine leap, because you are giving a non-human identity the power to act on production.
The danger spikes at a specific intersection some call the “lethal trifecta.” It happens when one agent has all three at once:
- Read access to private or sensitive data.
- Exposure to untrusted external content.
- A channel to act outward, like sending an email or firing a webhook.
Any one alone is fine. All three together is a breach waiting to happen.
🛑 The maturity gate before you grant write access
Before any agent gets write access, it needs hard limits. The cautionary tale is real. A support agent got stuck in a retry loop overnight, with no circuit breaker, and burned roughly $4,200 in API costs while the developer slept.
So we build two controls first. A hard circuit breaker that kills a runaway loop. And what I think of as “angry agents,” reviewers prompted to poke holes in the plan, because otherwise the human and the agent just agree with each other while the server burns. At Teamvoy, our AI agent development puts these controls in before write access, not after the incident report. Maturity, in the end, is just earning the right to let the model act.
Q6. How do you find your ROI position when token spend is climbing and output isn’t? [toc=6. ROI Position]
Your ROI position is the gap between what AI costs you and what it returns, and most leaders only see the return side. Token spend rarely scales linearly. Agent loops re-send their entire history, so cost grows quadratically. A 20-step loop is not twice a 10-step run. It is far pricier. Diagnose ROI by metering cost per outcome, not per call, and put a hard ceiling on every agent.
💸 A $150,000 bill with nothing to show
I have seen the invoice that starts the panic. Six figures in model spend, and the board asking what it bought. The honest answer is often “experiments.” That is the ROI position most teams are actually in, and they do not know it.
The trouble is leaders watch the output side and ignore the cost side. McKinsey’s 2025 survey found that even among AI users, only around 39% report any measurable bottom-line impact, usually under 5% of earnings. Gartner flagged rising, unpredictable cost as a top reason agentic projects get cancelled, which is why disciplined IT cost optimization matters here.
📈 The quadratic billing bomb, explained simply
Here is the mechanic almost nobody budgets for. Agent frameworks append every tool call, every error, and every step to the running history. Each new step re-sends the whole cumulative log back to the model.
So token cost grows quadratically, not linearly. A 20-step task is not twice a 10-step task. Because the history keeps re-sending, it is dramatically more expensive. The cost curve bends upward right when you start scaling, which is the worst possible moment to find out. Our AI integration cost guide breaks down where that money actually goes.
⏰ The nap that cost $4,200
The extreme version is memorable. An agent hit an infinite retry loop with a CRM tool overnight. With no hard ceiling, it repeated the same broken action for six hours and ran up about $4,200 while the developer slept.
That is not a freak event. It is the default outcome when nobody meters spend per outcome and nobody sets a cap.
✅ Three moves to fix your ROI position
Do these this week:
- Meter cost per outcome 💰, not cost per call. Tie spend to a resolved ticket or a closed task, not raw API usage.
- Set a hard circuit breaker on every agent, a spend ceiling that kills the run.
- Compact context often: compress the running history regularly so the agent keeps room to think and stops re-sending bloat.
My posture here is simple, work fast and transparently, with cost in view. At Teamvoy, our AI integration services instrument cost per outcome before we scale anything, not after the surprise invoice lands. You cannot manage an ROI position you have never measured.
Q7. Build, buy, or partner, how do you decide which AI move comes next? [toc=7. Build Buy or Partner]
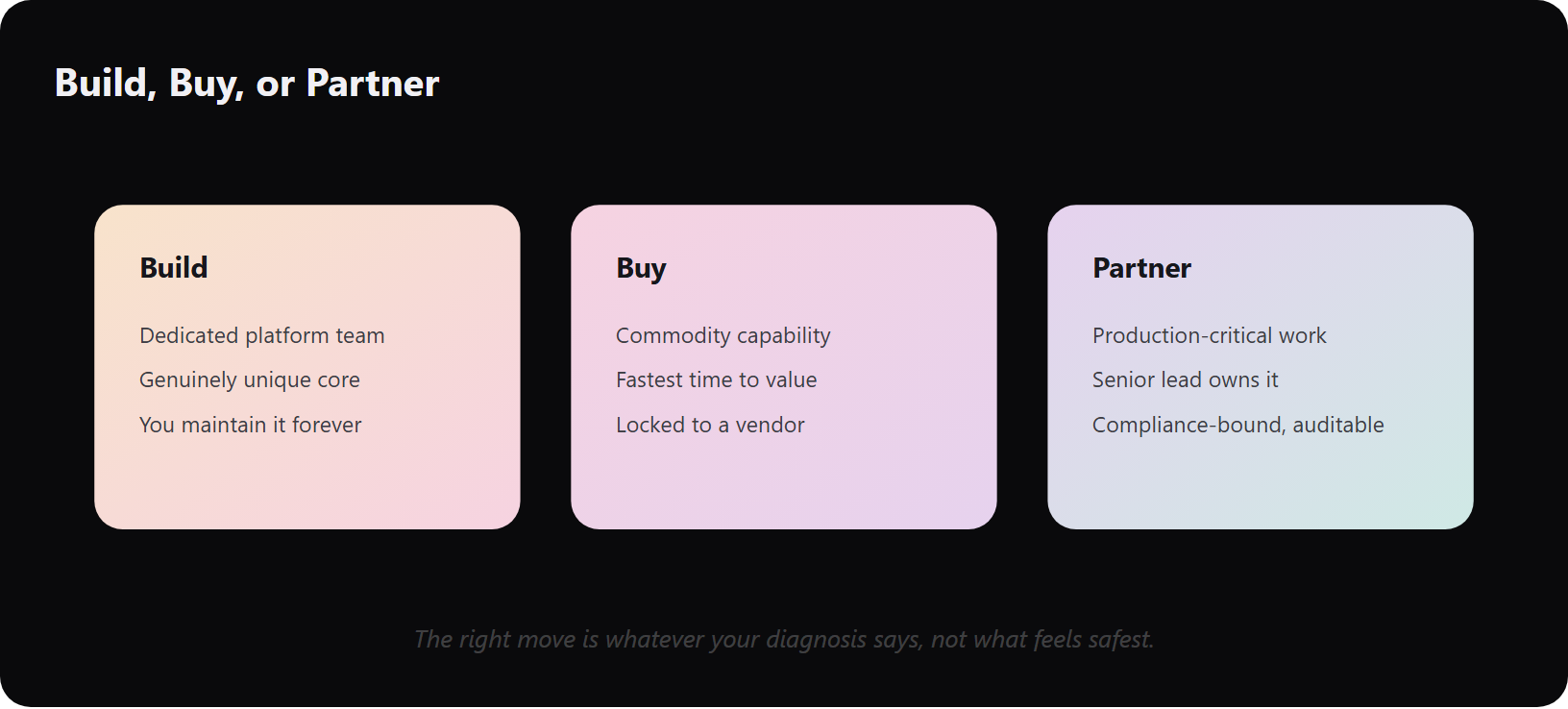
Once you have scored the four axes, the build-buy-partner decision follows the diagnosis instead of the hype. Build only with a dedicated platform team and genuinely unique core systems. Otherwise you become Chief Integration Officer forever, maintaining every schema, field mapping, and retry path. Buy for commodity capability. Partner when you need production-grade delivery and accountability you cannot staff internally.
🏗️ Building feels safer, until it owns you
Building in-house feels like control. It often becomes a quiet tax. The hidden cost of building your own integration layer is that you become Chief Integration Officer forever, maintaining every API schema, custom field mapping, authentication flow, and retry path. Clean system integration is harder to own than it looks.
I will say the unpopular part. There is a strong pull to “build the model” or own everything. As one well-known line goes, the model is not the product, it is the harness around it that matters. So building the model is rarely your edge.
📊 The decision matrix
Use your four-axis scores to read this table honestly.
| Criterion | Build | Buy | Partner |
|---|---|---|---|
| Core system uniqueness | 100% unique | Commodity | Unique but understaffed |
| Team in place | Dedicated platform team | None needed | Senior gap to fill ✅ |
| Time to value | Slowest | Fastest ⏰ | Fast, with ownership |
| Compliance burden | You own it all | Vendor-dependent | Shared, auditable |
| Supportability after | You maintain forever | Locked to vendor | Senior lead accountable |
The rule of thumb: build only if you have a dedicated platform team AND your core systems are genuinely unique.
🤝 When partnering actually wins
Partner when the work is production-critical, compliance-bound, and you cannot staff the senior ownership it needs. This is the territory Teamvoy is built for, the engagements other vendors decline, vendor rescues, compliance-blocked features, AI-built MVPs hitting their limit. A senior technical lead owns the system end to end, with an average engagement of 4+ years, not project-and-exit. If hiring is your constraint, you can also hire AI engineers directly.
I will name the trade-off, because you would find it anyway. ❌ Do not partner for commodity capability. If a tool buys it off the shelf, buy it. One client described the partner experience plainly:
“I have fully relied on Teamvoy’s technical decisions and it worked well… I can confidently say that we would not be where we are today without Teamvoy’s support.”
Gordon Little, Managing Director, Iress Teamvoy Clutch Verified Review
The right move is whatever your diagnosis says, not whatever feels most in control.
Q8. How do you set a measurable AI objective once you know where you stand? [toc=8. Set a Measurable Objective]
A measurable AI objective names one outcome, one metric, one deadline, and one owner, derived from your lowest-scoring axis, not your loudest stakeholder. If data readiness is the constraint, your objective is data, not agents. Tie every target to a monitored guardrail. Then size it to a 4-to-12 week move you can actually verify, not an 18-month “transformation” nobody can hold accountable.
🎯 The objective formula
By the end of this, you will be able to write one objective you can defend to a board. The formula is small on purpose:
- One outcome: the result, in plain words.
- One metric 💰: how you will know it happened.
- One deadline ⏰: a date, weeks not quarters.
- One owner: a named person, not a committee.
The key move: anchor the objective to your lowest-scoring axis. If data readiness scored a 2, your objective is data work, not agent deployment. You fix the constraint first.
📉 Why small verifiable moves beat big bets
The data argues against grand goals. McKinsey found 88% of organizations use AI, but only about a third have scaled past experiments. In one practitioner read of roughly 180 organizations, about 52% were still experimenting and only 22 to 23% had reached a formalization phase in 2025.
Most companies are stuck in experimentation. A bold 18-month goal does not fix that. A verifiable 4-to-12 week move does, because you can check it, learn, and decide again. This is the thinking behind our AI modernization sprints. Avoid the “automate everything” fallacy, the idea that you plan it in your head, hand it to an orchestrator, and walk away.
🔭 A worked example, and one caveat
Say your diagnosis flags governance as the weak axis. A weak objective is “adopt AI agents.” A real one is this. “Move our support agent from read-mode to write-mode for refund approvals under $50, with a circuit breaker and full audit log, owned by the platform lead, verified in 8 weeks.”
That you can measure. That you can defend. Here is the caveat I hold firmly. AI is a force multiplier, like night-vision goggles. They make trained soldiers more effective, but they are useless, even dangerous, on someone who never carried a weapon. Capability comes before scale.
At Teamvoy, the goal is not to drop in a technical solution. It is to help shape strategy, assess risk, and build the process that delivers a real result, the core of our AI consulting work. A 3-to-5-day audit surfaces your weakest axis and an action plan. It does not ship the implementation, that is the sprint that follows. Set the objective where the diagnosis points, and the next move stops being a guess.
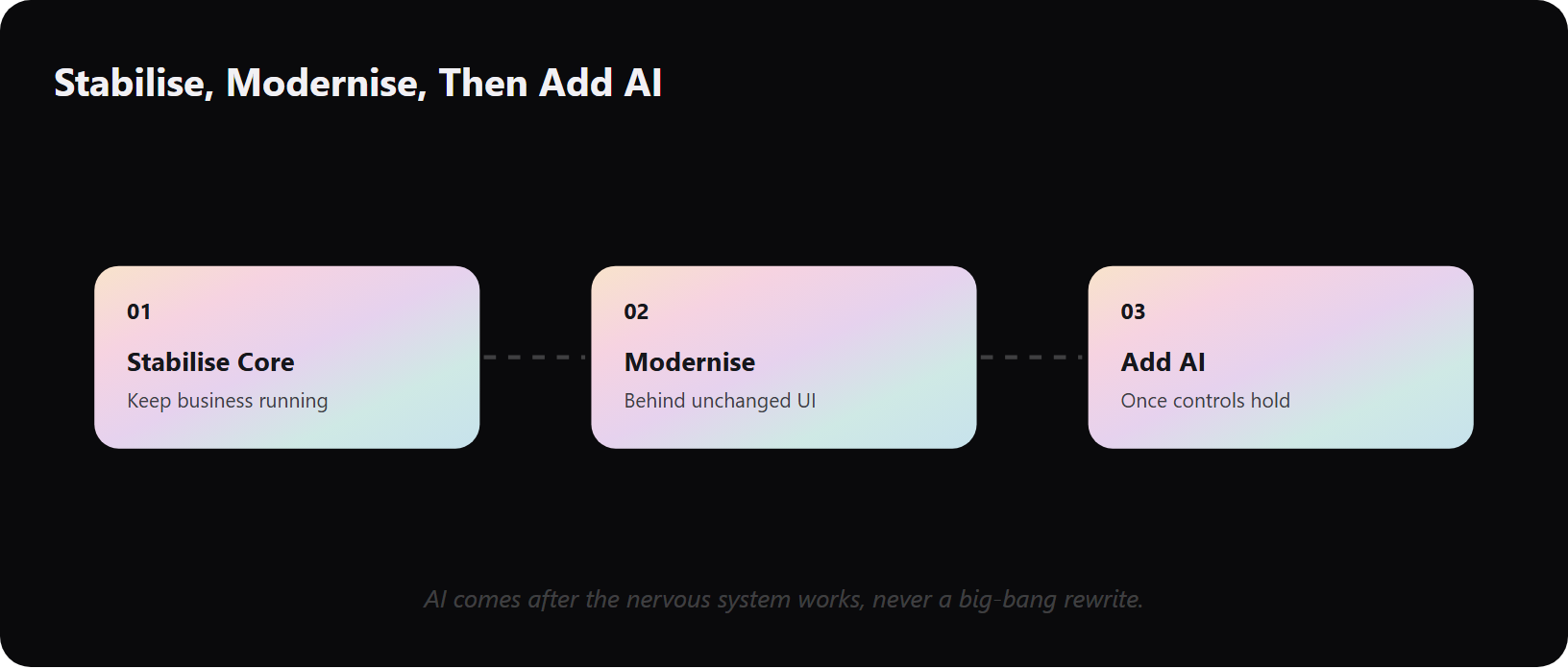
Q9. What does a stabilisation-first AI engagement look like in a regulated, legacy environment? [toc=9. Stabilisation-First Engagement]
In a regulated, legacy environment, the credible AI path is stabilise first, modernise incrementally, then add AI where the data and controls can support it, never a big-bang rewrite. You keep the business running, document the system the previous team left behind, and migrate behind an unchanged interface so users never feel the floor move. AI comes after the nervous system works, not before.
🌙 The 2 AM restart that taught me everything
Picture an on-call engineer at 2 AM. A server is down. He pastes the error into an AI tool, and it reads the docs and says, confidently, “restart the server.”
He restarts it. It breaks again. He restarts it six times before escalating. A senior engineer then reads the logs for about thirty seconds and sees it instantly. The database connection pool was full. That is tribal knowledge, the kind an AI does not have, because it never lived inside your system. This is why updating systems nobody understands starts with people, not tools.
🧠 Why AI starts every job with no memory
This is the heart of it. When AI jumps into your codebase, it has no memory of it. It is like the man in Memento, stepping in fresh, asking “okay, what am I doing?”.
So on a legacy core, the first work is not the model. It is stabilising and documenting what the previous team left behind. A legacy modernization is closer to renovating an occupied building than building a new one. People are still inside, working, while you rewire the walls, which is exactly what disciplined technology modernization protects against.
🛒 The migration nobody felt
Here is a pattern we have used to modernise without a rewrite. We rebuilt a system behind an interface that looked identical. Same colors, same button sizes, same screens the staff already knew.
Underneath, we wrote to very different, cleaner tables. The cashier came in the next day and saw the same system. Three weeks later, we added one new dropdown and taught that one change, normalizing the system one step at a time. The business never stopped. Nobody felt the floor move. The same incremental discipline underpins our data migration in insurance work.
⚠️ AI comes last, and sometimes a rewrite wins
Only after the core is stable and the data is clean do we add AI, with the governance controls from earlier in place. At Teamvoy, this is the lane we are built for, the engagements others decline, with a senior technical lead who owns the system end to end. Our AI integration services sit on top of that stabilised core. One client put the result simply, after we integrated AI and modernized their legacy stack:
“Teamvoy’s work has resulted in fewer issues and a better user experience… we’re impressed with their involvement in processes and quick completion of work.”
Dmytro Maryanych, Manager, Takflix Teamvoy Clutch Verified Review
I will name the honest limit. ❌ Modernization without a rewrite is not always possible. Sometimes the core is so far gone that a strategic rebuild is the cheaper, safer call, and we will tell you when that is the case. If your stack is buckling under tech debt, that is the first conversation to have.
Q10. Where do you go from here, what’s your next move and who owns it? [toc=10. Your Next Move]
Your next move is whatever your lowest-scoring axis tells you it is. Score data readiness, use-case feasibility, governance maturity, and ROI position from 1 to 5 each. The lowest number is your starting point, and the others are sequence, not simultaneity. Fix the constraint, set one measurable objective against it, and assign one owner. Then take a small, verifiable step, not a transformation.
📋 Your one-page score
Fill this in before you do anything else. Be honest, not generous.
| Axis | Score (1 to 5) | What a low score means |
|---|---|---|
| Data readiness ⭐ | – | Fix data before any model |
| Use-case feasibility | – | Re-scope or kill the demo darling |
| Governance maturity | – | Stay in read-mode for now |
| ROI position 💰 | – | Meter cost per outcome first |
🧭 Read the lowest number, then move
Your lowest score is your next move. Not your loudest stakeholder, not the demo that wowed the board. The constraint decides. A short IT audit can confirm which axis is really blocking you.
The others are sequence, not all at once. AI is a force multiplier, like night-vision goggles. They make a trained soldier sharper, but they are useless, even dangerous, on someone who never held a weapon. Build the capability under the weak axis before you scale anything on top of it, which is the core of our AI consulting approach.
🚪 The question I’m sitting with
Here is where my head is right now. I think the firms that win the next two years will not be the ones with the boldest AI goals. They will be the ones honest enough to diagnose first, then move in steps they can actually verify.
I could be wrong. But across twelve years and 150+ projects at Teamvoy, the pattern holds. Trust is built through results, not presentations. So if you have your four scores and you are staring at the lowest one, that is the real start of your strategy. Tell us what broke, or what you are building, and we will help you read the map. If you want proof of execution first, our case studies show the work.
Q1. What is an enterprise AI strategy, and why does diagnosis come before the goal? [toc=1. What It Is]
An enterprise AI strategy is a decision system that locates where your organization actually stands on four axes, data readiness, use-case feasibility, model and governance maturity, and ROI position, before it sets any objective. Its core components are data, use cases, governance, and economics. Most strategies fail because they start with a goal (“deploy agents this quarter”) instead of an honest diagnosis. You cannot set a credible target from a position you have not measured.
🧭 The board asked for a number, and the room went quiet
I have sat in that room. A board wants an “AI roadmap” by next quarter, and the Head of AI has three stalled pilots and a token bill nobody wants to explain. The instinct is to set a bold goal fast. That instinct is the problem.
The first thing I look at on an AI integration call is not the model. It is the data layer, then the legacy core. The model is the last question, not the first. One sharp framing I keep coming back to: we have been obsessing over the brain while ignoring the nervous system. Even a top-tier model is useless when it gets bad data or cannot execute actions reliably.
📊 Diagnosis-first beats goal-first, and the data says so
The numbers back this up. MIT’s Project NANDA found that roughly 95% of enterprise generative AI pilots delivered no measurable profit-and-loss impact. McKinsey’s 2025 survey found that while 88% of organizations use AI in some function, only about a third have scaled it past experiments.
Read those two together. Adoption is near-universal. Results are rare. The gap is not ambition. It is that most teams set a goal before they knew their own starting position. From what surfaces when you actually run these engagements, the firms that scale are the ones that measured first.
✅ The four axes you score before you set a target
Here is the frame the rest of this article runs on. Score yourself honestly on each before you commit to anything:
- Data readiness ⭐: is your data accessible, governed, and structured enough for a model to reason over.
- Use-case feasibility: will the use case survive production, not just a demo.
- Model and governance maturity: can you let a model act safely, with controls you can audit.
- ROI position 💰: do you know your cost per outcome, not just your spend.
At Teamvoy, every engagement I have led across 150+ delivered projects starts here, with a diagnosis, not a transformation pitch. Twelve years in regulated industries taught me one thing plainly. A goal set on top of an unmeasured stack is a guess wearing a deadline. This is the discipline behind our AI consulting work.
Your Monday action is small and uncomfortable. Score the four axes from 1 to 5, before you write a single objective. The lowest score is where your strategy actually begins.
Q2. Why do 95% of enterprise AI pilots stall, is your infrastructure broken or your execution? [toc=2. Why Pilots Stall]
Pilots stall for two distinct reasons that get blamed on each other. MIT’s NANDA study points to a learning and workflow gap, tools that never integrate into how work actually happens. Gartner and Deloitte point to data readiness and governance gaps. Both are real. Your job is to diagnose which one is blocking you, because the fix for a workflow gap is not the fix for a broken data layer.
🤔 The question every CTO is actually asking
Behind the polite roadmap conversation, the real question is quieter. “Is my infrastructure fundamentally broken for AI, or do I just need better prompts?” I have shipped production systems for a long time, and I will say it plainly. This is a new failure pattern, and it is everywhere right now.
The standard read gets this backwards. People assume one root cause. There are two, and they need opposite fixes.
🧠 The first story: it is a workflow gap
MIT’s Project NANDA framed the 95% failure rate as a learning and workflow problem. The tools work in a demo. They never get woven into how a team actually does the job. The pilot becomes a parallel toy, not a part of the workday.
I see this constantly. A team buys a clever tool, runs a flashy proof of concept, then nobody changes their actual process. The tool sits unused. That is not a broken server. That is a broken adoption path.
🗄️ The second story: it is a data and governance gap
Then there is the other camp. Gartner projected that more than 40% of agentic AI projects will be cancelled by the end of 2027, citing rising costs, unclear business value, and weak risk controls. Deloitte’s work on AI readiness puts data quality, governance maturity, and infrastructure as the things to assess before you deploy anything.
These two stories contradict each other, and I am not going to pretend they resolve neatly. MIT says the problem is rarely infrastructure. Gartner and Deloitte say infrastructure and governance are exactly where projects die. I think both are true, in different shops, which is why a generic “AI transformation” pitch helps neither.
A concrete tell of the execution-gap version: teams dump every Confluence doc, Slack thread, and Salesforce record into a vector database and hope the model figures it out. You do not get reasoning. You get thrashing and context-flooding. And the most expensive failure mode is code that is almost right. It passes review, ships, and sits wrong in your codebase for six months before anyone notices.
🔍 A two-line test to find your gap
Run this on Monday. First: pick your most-used pilot and ask, “did anyone change their daily workflow to use it.” If no, your gap is workflow. Second: ask your data team, “can we retrieve one specific fact for one customer, cleanly, in under a minute.” If no, your gap is data.
This is the work we do at Teamvoy before proposing anything, name which gap you actually have. An independent IT audit often surfaces it fast. The fix you fund should match the gap you found, not the one a vendor deck assumed.
Q3. How do you diagnose your data readiness for AI? [toc=3. Data Readiness]
Data readiness is not how much data you have. It is whether the data is accessible, governed, and structured enough for a model to reason over it. Diagnose it across four checks: data quality and lineage, access and permissions, structure (can a model retrieve one fact without context-flooding), and a “scream test” for zombie data. Loading your whole hard drive into a vector database is not readiness. It is thrashing.
📦 “We have tons of data” is a trap, not a head start
The most confident sentence I hear on a readiness call is “we have all the data we need.” It is usually wrong. Volume is not readiness. A warehouse full of unlabeled, duplicated, half-owned data is a liability the moment a model tries to use it.
By the end of this section, you will be able to run four concrete checks and walk away with a 1-to-5 readiness score. These map to the dimensions analysts like TDWI use in their data governance and AI-readiness models, quality, access, structure, and lifecycle. Getting these right is the foundation of any serious data engineering effort.
✅ The four readiness checks, and what each should tell you
Run each check and note the expected outcome:
- Quality and lineage ⭐: can you trace where a field came from and trust it. Expected outcome: you can name the source system and last-validated date for your top 20 fields.
- Access and permissions: can the right system reach the right data, with the wrong access blocked. Expected outcome: a clear map of who and what can read each dataset.
- Structure: can a model retrieve one fact without dragging in noise. Expected outcome: a single query returns one clean answer, not a flood.
- Lifecycle (the scream test) ⚠️: do you know which data is still alive. Expected outcome: a list of suspected dead, or “zombie,” datasets to test.
🧪 Why structure matters more than people expect
Here is the part most strategies skip. Models have a working-memory limit. Push past roughly 40% of the context window and quality drops, the model effectively gets dumber as the context fills with junk. If your retrieval dumps raw JSON and IDs into that window, you are doing the real work in the dumb zone.
This is why the “dump everything into a vector database” pattern fails. It is like dumping your entire hard drive into RAM and asking the CPU to find one byte. You get context-flooding, not answers. Structure is what lets a model find the one fact that matters.
🔇 The scream test for zombie data
My favorite tactical move costs almost nothing. Temporarily isolate a suspected dead dataset at the network level for 48 to 72 hours. Then watch who screams.
That window reveals hidden dependencies standard monitoring misses, a monthly batch job, a quarterly audit export, a report nobody documented. At Teamvoy, on the modernization engagements I have led, the data layer is question one and the legacy core is question two. The model is always last. Trust me, the boring data work is where AI projects are quietly won or lost.
Q4. How do you score AI use-case feasibility instead of chasing the demo? [toc=4. Use-Case Feasibility]
Use-case feasibility is whether a use case survives production, not whether it dazzles in a demo. Score each candidate on business impact, data availability, integration cost, and supportability, can your team read, maintain, and explain the system afterward. A demo that “feels like magic” but produces code nobody understands is not feasible. It is debt with a deadline.
🎩 The demo was magic, so why is nothing shipping
I have watched a brilliant demo win a budget, then watched the same project stall for a year. The demo is designed to impress. Production is designed to break you. The board sees the magic and asks, six months later, why nothing has shipped.
The honest answer is usually that the use case was never feasible. It was just photogenic. Here is the rubric I use to score candidates before anyone commits.
📋 The feasibility scoring matrix
Score each use case 1 to 5 on four criteria. Add them. Anything under 12 needs a hard second look.
| Criterion | What a high score looks like | Not feasible for you if |
|---|---|---|
| Business impact 💰 | Tied to a real metric, revenue or cost | Nobody can name the metric it moves |
| Data availability | The data exists, clean and reachable | You would have to build the data first |
| Integration cost | Plugs into existing systems cleanly | It needs a custom integration layer per system |
| Supportability ✅ | Your team can read and maintain it | Only the original AI prompt “understands” it |
That last row is the one most strategies ignore, and it is the one I weigh hardest.
🏗️ Vibe coding is a technical-debt factory
There is a trend where developers describe software in natural language and let AI “vibe” it into existence. It feels like magic in the demo. The trouble is that AI-generated code tends to be simpler, more repetitive, and dangerously less structurally diverse. It lacks the connective tissue a system needs to stay robust.
The receipts are ugly. One analysis found a 4x surge in code cloning, where AI copies similar blocks instead of building reusable logic. A security review of 5,000 vibe-coded apps found 60% were vulnerable, the digital equivalent of no locks on the windows. Code that ships still has to be supported in production by people who can read it, which is exactly why vibe coding security risks compound so fast.
❓ The three-question gate before you greenlight
Before any AI-built feature goes to production, we run a simple review on the pull request:
- Does it reuse what already exists, or reinvent it.
- Does it follow your conventions.
- Can the developer explain it without reading the AI’s comments.
If the answer to the third is no, the code is unmaintainable, and unmaintainable code is already dead. At Teamvoy, supportability is a feasibility criterion, not an afterthought, because we are often the team called in for AI development when an AI-built MVP hits its limit. One client put the payoff plainly after we integrated AI and modernized their legacy stack:
“Teamvoy’s work has resulted in fewer issues and a better user experience… we’re impressed with their involvement in processes and quick completion of work.” Dmytro Maryanych, Manager, Takflix Teamvoy Clutch Verified Review
Feasibility, in the end, is just honesty about what your team can carry after the demo applause stops.
Q5. What does model and governance maturity look like, and why is “write access” the real line? [toc=5. Governance Maturity]
Governance maturity is your ability to safely let a non-deterministic model act, not just answer. Benchmark it against NIST AI RMF (Govern, Map, Measure, Manage) and ISO/IEC 42001. The real maturity line is read-mode versus write-mode. Almost every enterprise agent today only reads. Giving a non-deterministic, non-human identity write access to a production system is the leap, and it demands controls most organizations have not built.
🔐 The 2 AM fear nobody says out loud
Here is the thing that keeps a careful CTO up at night. A model with write access can change a production record, send a payment, or email a customer. It is non-deterministic, meaning it can give a different answer to the same question twice. You are handing the keys to something that does not reason like a person.
I have delivered into regulated environments for years, BaFin, PSD2, DORA, HIPAA, GDPR. In those worlds, downtime is a reportable event, not an inconvenience. So I will state the governing thought plainly. Maturity is not which model you picked. It is whether you can let that model act and still sleep, which is the heart of building regulator-ready AI in fintech.
📐 Pillar one: benchmark against named frameworks
Do not invent your governance from scratch. Two named, dated standards already exist:
- NIST AI Risk Management Framework ✅: organized around four functions, Govern, Map, Measure, and Manage, with a generative-AI profile added in 2024.
- ISO/IEC 42001: a certifiable AI management-system standard you can audit against.
Score yourself against these. If you cannot say which NIST function your controls cover, that is your maturity gap, in writing. A structured IT audit is the fastest way to surface it.
⚠️ Pillar two: read-mode is safe, write-mode is the leap
Almost every enterprise agent today is in read mode. It looks things up. It summarizes. It answers. Getting to write access, where the agent changes the system, is a genuine leap, because you are giving a non-human identity the power to act on production.
The danger spikes at a specific intersection some call the “lethal trifecta.” It happens when one agent has all three at once:
- Read access to private or sensitive data.
- Exposure to untrusted external content.
- A channel to act outward, like sending an email or firing a webhook.
Any one alone is fine. All three together is a breach waiting to happen.
🛑 The maturity gate before you grant write access
Before any agent gets write access, it needs hard limits. The cautionary tale is real. A support agent got stuck in a retry loop overnight, with no circuit breaker, and burned roughly $4,200 in API costs while the developer slept.
So we build two controls first. A hard circuit breaker that kills a runaway loop. And what I think of as “angry agents,” reviewers prompted to poke holes in the plan, because otherwise the human and the agent just agree with each other while the server burns. At Teamvoy, our AI agent development puts these controls in before write access, not after the incident report. Maturity, in the end, is just earning the right to let the model act.
Q6. How do you find your ROI position when token spend is climbing and output isn’t? [toc=6. ROI Position]
Your ROI position is the gap between what AI costs you and what it returns, and most leaders only see the return side. Token spend rarely scales linearly. Agent loops re-send their entire history, so cost grows quadratically. A 20-step loop is not twice a 10-step run. It is far pricier. Diagnose ROI by metering cost per outcome, not per call, and put a hard ceiling on every agent.
💸 A $150,000 bill with nothing to show
I have seen the invoice that starts the panic. Six figures in model spend, and the board asking what it bought. The honest answer is often “experiments.” That is the ROI position most teams are actually in, and they do not know it.
The trouble is leaders watch the output side and ignore the cost side. McKinsey’s 2025 survey found that even among AI users, only around 39% report any measurable bottom-line impact, usually under 5% of earnings. Gartner flagged rising, unpredictable cost as a top reason agentic projects get cancelled, which is why disciplined IT cost optimization matters here.
📈 The quadratic billing bomb, explained simply
Here is the mechanic almost nobody budgets for. Agent frameworks append every tool call, every error, and every step to the running history. Each new step re-sends the whole cumulative log back to the model.
So token cost grows quadratically, not linearly. A 20-step task is not twice a 10-step task. Because the history keeps re-sending, it is dramatically more expensive. The cost curve bends upward right when you start scaling, which is the worst possible moment to find out. Our AI integration cost guide breaks down where that money actually goes.
⏰ The nap that cost $4,200
The extreme version is memorable. An agent hit an infinite retry loop with a CRM tool overnight. With no hard ceiling, it repeated the same broken action for six hours and ran up about $4,200 while the developer slept.
That is not a freak event. It is the default outcome when nobody meters spend per outcome and nobody sets a cap.
✅ Three moves to fix your ROI position
Do these this week:
- Meter cost per outcome 💰, not cost per call. Tie spend to a resolved ticket or a closed task, not raw API usage.
- Set a hard circuit breaker on every agent, a spend ceiling that kills the run.
- Compact context often: compress the running history regularly so the agent keeps room to think and stops re-sending bloat.
My posture here is simple, work fast and transparently, with cost in view. At Teamvoy, our AI integration services instrument cost per outcome before we scale anything, not after the surprise invoice lands. You cannot manage an ROI position you have never measured.
Q7. Build, buy, or partner, how do you decide which AI move comes next? [toc=7. Build Buy or Partner]
Once you have scored the four axes, the build-buy-partner decision follows the diagnosis instead of the hype. Build only with a dedicated platform team and genuinely unique core systems. Otherwise you become Chief Integration Officer forever, maintaining every schema, field mapping, and retry path. Buy for commodity capability. Partner when you need production-grade delivery and accountability you cannot staff internally.
🏗️ Building feels safer, until it owns you
Building in-house feels like control. It often becomes a quiet tax. The hidden cost of building your own integration layer is that you become Chief Integration Officer forever, maintaining every API schema, custom field mapping, authentication flow, and retry path. Clean system integration is harder to own than it looks.
I will say the unpopular part. There is a strong pull to “build the model” or own everything. As one well-known line goes, the model is not the product, it is the harness around it that matters. So building the model is rarely your edge.
📊 The decision matrix
Use your four-axis scores to read this table honestly.
| Criterion | Build | Buy | Partner |
|---|---|---|---|
| Core system uniqueness | 100% unique | Commodity | Unique but understaffed |
| Team in place | Dedicated platform team | None needed | Senior gap to fill ✅ |
| Time to value | Slowest | Fastest ⏰ | Fast, with ownership |
| Compliance burden | You own it all | Vendor-dependent | Shared, auditable |
| Supportability after | You maintain forever | Locked to vendor | Senior lead accountable |
The rule of thumb: build only if you have a dedicated platform team AND your core systems are genuinely unique.
🤝 When partnering actually wins
Partner when the work is production-critical, compliance-bound, and you cannot staff the senior ownership it needs. This is the territory Teamvoy is built for, the engagements other vendors decline, vendor rescues, compliance-blocked features, AI-built MVPs hitting their limit. A senior technical lead owns the system end to end, with an average engagement of 4+ years, not project-and-exit. If hiring is your constraint, you can also hire AI engineers directly.
I will name the trade-off, because you would find it anyway. ❌ Do not partner for commodity capability. If a tool buys it off the shelf, buy it. One client described the partner experience plainly:
“I have fully relied on Teamvoy’s technical decisions and it worked well… I can confidently say that we would not be where we are today without Teamvoy’s support.” Gordon Little, Managing Director, Iress Teamvoy Clutch Verified Review
The right move is whatever your diagnosis says, not whatever feels most in control.
Q8. How do you set a measurable AI objective once you know where you stand? [toc=8. Set a Measurable Objective]
A measurable AI objective names one outcome, one metric, one deadline, and one owner, derived from your lowest-scoring axis, not your loudest stakeholder. If data readiness is the constraint, your objective is data, not agents. Tie every target to a monitored guardrail. Then size it to a 4-to-12 week move you can actually verify, not an 18-month “transformation” nobody can hold accountable.
🎯 The objective formula
By the end of this, you will be able to write one objective you can defend to a board. The formula is small on purpose:
- One outcome: the result, in plain words.
- One metric 💰: how you will know it happened.
- One deadline ⏰: a date, weeks not quarters.
- One owner: a named person, not a committee.
The key move: anchor the objective to your lowest-scoring axis. If data readiness scored a 2, your objective is data work, not agent deployment. You fix the constraint first.
📉 Why small verifiable moves beat big bets
The data argues against grand goals. McKinsey found 88% of organizations use AI, but only about a third have scaled past experiments. In one practitioner read of roughly 180 organizations, about 52% were still experimenting and only 22 to 23% had reached a formalization phase in 2025.
Most companies are stuck in experimentation. A bold 18-month goal does not fix that. A verifiable 4-to-12 week move does, because you can check it, learn, and decide again. This is the thinking behind our AI modernization sprints. Avoid the “automate everything” fallacy, the idea that you plan it in your head, hand it to an orchestrator, and walk away.
🔭 A worked example, and one caveat
Say your diagnosis flags governance as the weak axis. A weak objective is “adopt AI agents.” A real one is this. “Move our support agent from read-mode to write-mode for refund approvals under $50, with a circuit breaker and full audit log, owned by the platform lead, verified in 8 weeks.”
That you can measure. That you can defend. Here is the caveat I hold firmly. AI is a force multiplier, like night-vision goggles. They make trained soldiers more effective, but they are useless, even dangerous, on someone who never carried a weapon. Capability comes before scale.
At Teamvoy, the goal is not to drop in a technical solution. It is to help shape strategy, assess risk, and build the process that delivers a real result, the core of our AI consulting work. A 3-to-5-day audit surfaces your weakest axis and an action plan. It does not ship the implementation, that is the sprint that follows. Set the objective where the diagnosis points, and the next move stops being a guess.
Q9. What does a stabilisation-first AI engagement look like in a regulated, legacy environment? [toc=9. Stabilisation-First Engagement]
In a regulated, legacy environment, the credible AI path is stabilise first, modernise incrementally, then add AI where the data and controls can support it, never a big-bang rewrite. You keep the business running, document the system the previous team left behind, and migrate behind an unchanged interface so users never feel the floor move. AI comes after the nervous system works, not before.
🌙 The 2 AM restart that taught me everything
Picture an on-call engineer at 2 AM. A server is down. He pastes the error into an AI tool, and it reads the docs and says, confidently, “restart the server.”
He restarts it. It breaks again. He restarts it six times before escalating. A senior engineer then reads the logs for about thirty seconds and sees it instantly. The database connection pool was full. That is tribal knowledge, the kind an AI does not have, because it never lived inside your system. This is why updating systems nobody understands starts with people, not tools.
🧠 Why AI starts every job with no memory
This is the heart of it. When AI jumps into your codebase, it has no memory of it. It is like the man in Memento, stepping in fresh, asking “okay, what am I doing?”.
So on a legacy core, the first work is not the model. It is stabilising and documenting what the previous team left behind. A legacy modernization is closer to renovating an occupied building than building a new one. People are still inside, working, while you rewire the walls, which is exactly what disciplined technology modernization protects against.
🛒 The migration nobody felt
Here is a pattern we have used to modernise without a rewrite. We rebuilt a system behind an interface that looked identical. Same colors, same button sizes, same screens the staff already knew.
Underneath, we wrote to very different, cleaner tables. The cashier came in the next day and saw the same system. Three weeks later, we added one new dropdown and taught that one change, normalizing the system one step at a time. The business never stopped. Nobody felt the floor move. The same incremental discipline underpins our data migration in insurance work.
⚠️ AI comes last, and sometimes a rewrite wins
Only after the core is stable and the data is clean do we add AI, with the governance controls from earlier in place. At Teamvoy, this is the lane we are built for, the engagements others decline, with a senior technical lead who owns the system end to end. Our AI integration services sit on top of that stabilised core. One client put the result simply, after we integrated AI and modernized their legacy stack:
“Teamvoy’s work has resulted in fewer issues and a better user experience… we’re impressed with their involvement in processes and quick completion of work.” Dmytro Maryanych, Manager, Takflix Teamvoy Clutch Verified Review
I will name the honest limit. ❌ Modernization without a rewrite is not always possible. Sometimes the core is so far gone that a strategic rebuild is the cheaper, safer call, and we will tell you when that is the case. If your stack is buckling under tech debt, that is the first conversation to have.
Q10. Where do you go from here, what’s your next move and who owns it? [toc=10. Your Next Move]
Your next move is whatever your lowest-scoring axis tells you it is. Score data readiness, use-case feasibility, governance maturity, and ROI position from 1 to 5 each. The lowest number is your starting point, and the others are sequence, not simultaneity. Fix the constraint, set one measurable objective against it, and assign one owner. Then take a small, verifiable step, not a transformation.
📋 Your one-page score
Fill this in before you do anything else. Be honest, not generous.
| Axis | Score (1 to 5) | What a low score means |
|---|---|---|
| Data readiness ⭐ | – | Fix data before any model |
| Use-case feasibility | – | Re-scope or kill the demo darling |
| Governance maturity | – | Stay in read-mode for now |
| ROI position 💰 | – | Meter cost per outcome first |
🧭 Read the lowest number, then move
Your lowest score is your next move. Not your loudest stakeholder, not the demo that wowed the board. The constraint decides. A short IT audit can confirm which axis is really blocking you.
The others are sequence, not all at once. AI is a force multiplier, like night-vision goggles. They make a trained soldier sharper, but they are useless, even dangerous, on someone who never held a weapon. Build the capability under the weak axis before you scale anything on top of it, which is the core of our AI consulting approach.
🚪 The question I’m sitting with
Here is where my head is right now. I think the firms that win the next two years will not be the ones with the boldest AI goals. They will be the ones honest enough to diagnose first, then move in steps they can actually verify.
I could be wrong. But across twelve years and 150+ projects at Teamvoy, the pattern holds. Trust is built through results, not presentations. So if you have your four scores and you are staring at the lowest one, that is the real start of your strategy. Tell us what broke, or what you are building, and we will help you read the map. If you want proof of execution first, our case studies show the work.

