

TL;DR
- AI MVP development fails in production when teams pick the model first instead of auditing the data layer, accuracy baseline, and architecture.
- Route queries by complexity across cheaper and premium models to cut inference costs by up to 96% at scale.
- Work the layers in order: prompt engineering first, RAG second, and fine-tuning only when both have plateaued.
- A production AI MVP costs roughly $15,000 to $60,000 to build, with the quadratic billing bomb being the hidden agent-loop risk.
- The five most expensive mistakes are missing circuit breakers, no eval baseline, Dumb RAG, weak access controls, and undocumented tribal knowledge.
- Compliance (GDPR, HIPAA, EU AI Act) belongs on the intake form, not the launch checklist, especially in regulated industries.
Q1: What Is an AI MVP, and Why Do 95% of AI Pilots Never Reach Production?
A CTO at a Series A fintech startup shows me a Slack message. It is from six months ago. Their AI assistant demo had just gone viral internally. The team was celebrating. Today, that demo is a frozen repo. Not a single user query has ever hit production.
That scene repeats itself constantly. The demo works. The production system never gets built.
The Gap Nobody Talks About
An AI MVP (Minimum Viable Product) is not a chatbot demo. It is the smallest production-grade system that routes real user inputs to a language model, executes real actions, and returns measurable results, without requiring a full rebuild to scale.
A demo needs to impress once. An MVP needs to survive Monday morning, and the Monday after that.
The distinction matters because 95% of enterprise generative AI pilots have failed to deliver a single dollar of measurable return. That is not a model problem. That is an architecture problem, and it usually gets made in the first 48 hours.
Why Pilots Die Before Production
Three failure patterns show up in almost every stalled pilot I have seen.
The wrong first question. Most teams start by asking: “Which model should we use?” The right first question is: “What does our data layer look like, and does this system need to stay live while we build?”
No measurable outcome defined. A pilot succeeds when it impresses. An MVP succeeds when it moves a metric. If you cannot name the metric before you write the first line of code, you are building a demo with extra steps.
Architecture debt borrowed on day one. The fastest-to-demo choices (unstructured data in a vector database, no circuit breakers on API calls, no evaluation baseline) become the hardest-to-fix production problems six weeks later. You are not saving time. You are borrowing it at a high rate.
What the Architecture Decision Actually Determines
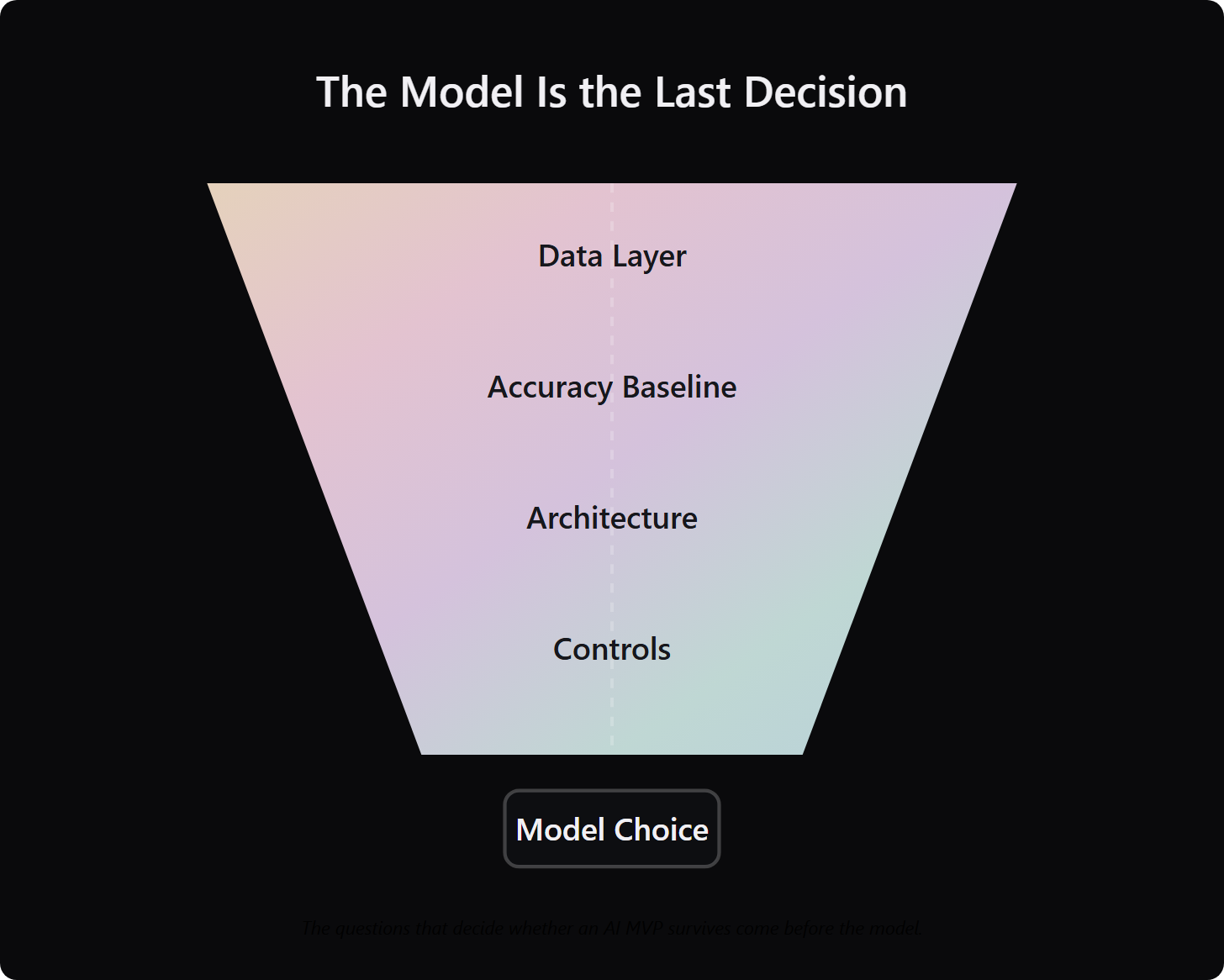
The model you pick is not what determines whether your AI MVP reaches production. It is what you build around the model.
The harness, the retrieval layer, the evaluation pipeline, the circuit breakers, the spend controls, the data schema, and the observability stack: those are the product. The model is a component inside it. This is why our AI integration services always begin with the system, not the model.
At Teamvoy, the first call with a founder who has a working demo is almost always about the data layer, not the model. What data does this system need to return accurate answers? Is that data clean, structured, and accessible? Can the system stay live while we integrate? Those questions take ten minutes. The answers determine the next ten weeks. If you want a structured look at where the risk sits, our IT audit services exist for exactly that.
The next three sections cover the three architectural decisions that separate a production AI system from a very expensive demo.
Q2: Which Foundation Model API Should You Build On, and What Does the Choice Actually Cost You?
The first sprint invoice that lands at $8,400 in API costs is always a shock. Not because the team was careless. Because nobody measured what development traffic actually looks like before committing to the flagship model.
Development traffic is typically 3 to 5 times production volume. You are running the same queries over and over, testing edge cases, and debugging prompts. If you are doing that on GPT-4o at full price, you will burn through a meaningful budget before a single real user touches the system. Our AI integration cost guide breaks down where this spend actually goes.
The Model Is Not the Product
Sam Altman framed this precisely: the model is a means to an end. The harness, the retrieval layer, and everything built around the model is what the product actually is. That realization changes how you approach model selection entirely.
You do not need the most powerful model. You need the cheapest model that clears your accuracy bar. Then you instrument it, measure it, and upgrade only if the data tells you to.
💰 Foundation Model API Comparison (2026)
| Model | Provider | Input $/1M tokens | Output $/1M tokens | Context Window | Open-Source | MVP Verdict |
|---|---|---|---|---|---|---|
| GPT-4o | OpenAI | $2.50 | $10.00 | 128K | No | Use for complex reasoning only |
| GPT-4o Mini | OpenAI | $0.15 | $0.60 | 128K | No | Best default for most MVPs |
| Claude 3.5 Sonnet | Anthropic | $3.00 | $15.00 | 200K | No | Strong for long-document tasks |
| Claude 3 Haiku | Anthropic | $0.25 | $1.25 | 200K | No | Fastest Anthropic option for MVP |
| Gemini 1.5 Pro | $3.50 | $10.50 | 1M | No | Best for very long context windows | |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M | No | Cheapest per-token option available | |
| Llama 3 70B (Groq) | Meta/Groq | ~$0.59 | ~$0.79 | 8K | Yes | Self-hostable; strong cost floor |
| Mistral 7B | Mistral | ~$0.25 | ~$0.25 | 32K | Yes | Lightweight; good for classification |
⭐ Route by Complexity, Save Up to 96%
A smarter approach: do not pick one model for all queries. Route by task type.
- Text formatting, extraction, and classification go to Gemini 1.5 Flash or GPT-4o Mini.
- Multi-step reasoning and synthesis go to GPT-4o or Claude 3.5 Sonnet.
- High-volume, latency-sensitive tasks go to Groq-hosted Llama 3.
This single pattern, routing basic operations to cheaper models and reserving expensive models for high-level reasoning, cuts inference costs by as much as 96% at scale. It is a core part of how our AI development services control cost from day one.
A Real Scenario
A customer support MVP running 1,000 queries per day costs roughly $18 per month on Gemini 1.5 Flash versus $300 per month on GPT-4o. In A/B testing on this class of task, user satisfaction scores are not materially different at that volume.
We see the same pattern in almost every engagement at Teamvoy: model selection gets made in week one, before anyone has profiled the actual query distribution. The right order is to instrument first, benchmark second, and commit to a model third. Set spend caps before you write the first prompt.
Q3: RAG, Fine-Tuning, or Prompt Engineering, Which Approach Actually Fits Your MVP?
A founder walks into an engagement having already spent $22,000 on fine-tuning. Their model can output answers in the right format. The answers are wrong 40% of the time. The root problem: the knowledge the model needed was sitting in a Confluence wiki that nobody had bothered to structure before the fine-tuning run started.
Fine-tuning does not fix a data problem. It encodes it.
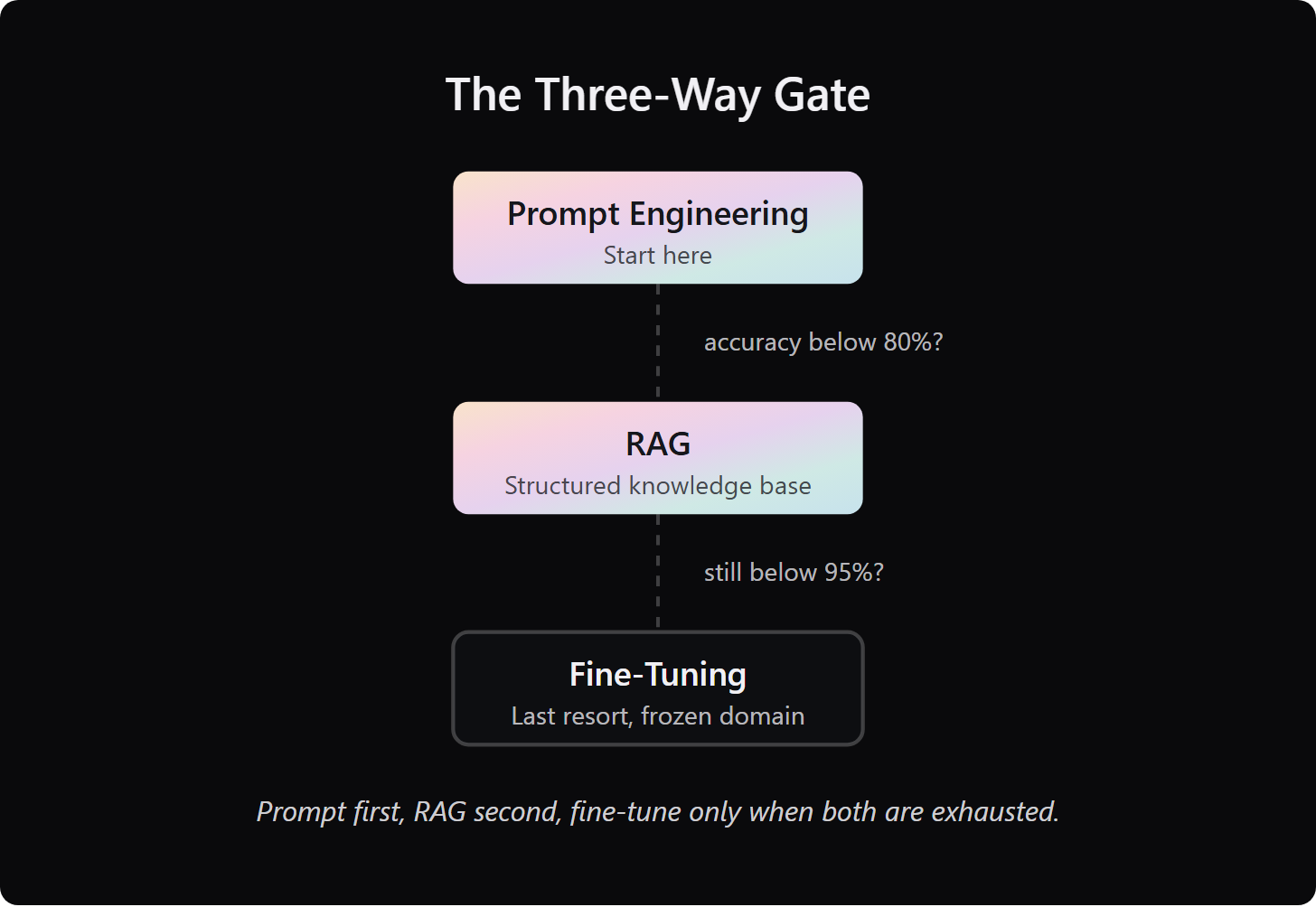
The real decision is a three-way gate, not a binary comparison. The sequence is: prompt engineering first, RAG second, and fine-tuning only when the previous layer has been genuinely exhausted.
⭐ What RAG Actually Is, and Where It Breaks
RAG (Retrieval-Augmented Generation) is an architecture pattern. At inference time, the system retrieves relevant text chunks from an external knowledge source, injects them into the model’s context window, and then generates a response grounded in that retrieved content.
Done correctly, RAG keeps responses current, auditable, and domain-specific, without touching model weights at all.
Done poorly, it becomes what I call Dumb RAG: teams dump their entire Confluence history, Slack logs, and Salesforce exports into a vector database (a database that stores text as numerical embeddings for similarity search) and hope the model figures it out. This approach treats the vector database like a hard drive and expects the CPU to find one specific byte. You do not get reasoning. You get thrashing and context flooding.
There is a second mechanical limit: most context windows degrade around the 40% fill mark. In a 128,000-token context window, that is roughly 51,000 tokens. Beyond that threshold, model accuracy falls measurably. If your RAG pipeline is consistently filling the context window, you are doing all your work in the dumb zone. The fix is aggressive chunking, metadata filtering, and re-ranking, not a bigger model. This is the kind of work our data engineering team handles before any model is selected.
❌ When Fine-Tuning Is the Wrong Call
Fine-tuning changes the actual weights of a model. It is appropriate when your accuracy requirement is above 95%, prompt engineering and RAG together have plateaued at 70 to 80%, and your domain knowledge is stable enough that a retraining cadence is manageable.
The hidden costs of fine-tuning are not GPU time. They are data labeling, the evaluation pipeline, the retraining schedule, and the model version you now have to maintain and redeploy every time your domain knowledge shifts.
Jake Heller, co-founder of CaseText, pushed a single prompt over two weeks of intensive work to 97% accuracy before resorting to any technical fine-tuning. That is the right sequence. Most teams skip directly to fine-tuning because it feels more technical and more permanent. Both of those feelings are exactly the problem.
One important caveat: a 2024 empirical study by Rouzrokh et al. found that fine-tuning outperforms RAG on narrow classification tasks with frozen domain knowledge. Lewis et al.’s original 2020 RAG paper showed the opposite for broad, knowledge-intensive tasks. The honest answer is that neither approach wins universally. The task type determines the winner.
✅ The 3-Way Decision Matrix
| Criteria | Prompt Engineering | RAG | Fine-Tuning |
|---|---|---|---|
| Data freshness need | High (real-time OK) | High (real-time OK) | Low (frozen domain) |
| Accuracy ceiling | 70 to 80% | 80 to 90% | 95%+ |
| Time to build | Days | 2 to 4 weeks | 6 to 10 weeks |
| Ongoing maintenance | Low | Medium (data pipeline) | High (retraining cadence) |
| Team skill required | Low | Medium | High |
| When to use | Domain is unstable; quick iteration | Knowledge base exists; answers need to be current | Rigid output format; frozen domain; tone consistency |
| When NOT to use | Accuracy above 80% required | Knowledge changes daily; no structured data | Budget under $30K; domain still evolving |
Teamvoy’s decision gate before any fine-tuning recommendation: run a 150-question labeled evaluation set against the use case. The results tell you exactly where the accuracy ceiling sits and which layer breaks through it most cost-efficiently. If the client has not yet run that evaluation, that is what we do first as part of our AI consulting engagement.
“Teamvoy actively uses agentic AI across internal workflows and delivery, which speeds up development, raises quality, and adds extra value for the client.”
Manager, Takflix Teamvoy Clutch Verified Review
Q4: How Do You Build an AI MVP Step by Step, From First Prompt to Production?
Most AI MVP builds fail at step three. Not because the team is incompetent, but because they started at step three. They selected a model, opened the API docs, and started building before they had defined a measurable outcome or looked at the data layer underneath.
Adding AI to a system without understanding the data layer is like adding a turbocharger to an engine that already misfires. The power increase is real. So is the risk.
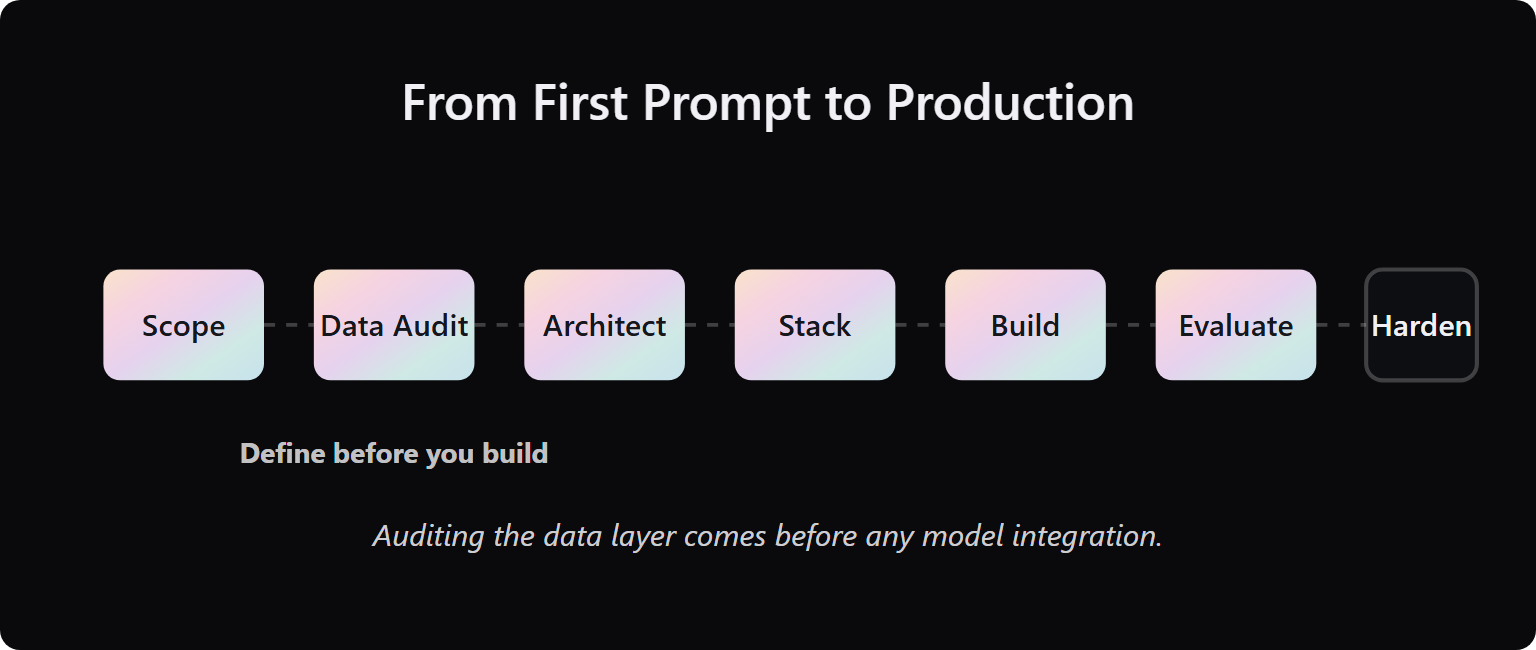
⭐ Steps 1 to 3: Define Before You Build
Step 1: Scope to a single measurable outcome. Not “add AI to the product.” Something specific: “Reduce first-response time for customer support tickets from 4 hours to 30 minutes, measured over 30 days.” If you cannot write the success metric before touching code, the MVP has no finish line.
Step 2: Audit the data layer. Before you choose a model or an architecture, answer these questions: What data does this system need to return accurate answers? Is it structured or unstructured? Is it accessible via API or locked in PDFs? How fresh does it need to be? The data audit determines the architecture, not the other way around. For systems built by previous teams, our guide on updating systems nobody understands covers this in depth.
AI has no memory when it enters a new codebase. It has never seen your system before. Without a documented data map, the model is the guy from Memento stepping in and saying “Okay, I’m here. What am I doing?” The nervous system has to be ready before the brain can do anything useful.
Step 3: Choose architecture. Use the decision matrix from the previous section. Prompt-only if the domain is small and stable. RAG if you have a structured knowledge base. Fine-tuning only after the first two layers have been tested and measured.
⚠️ Steps 4 to 5: Build the Minimum Pipeline
Step 4: Select the stack. Model API, vector database (if RAG), orchestration framework (LangChain or LlamaIndex), and observability layer. Do not over-engineer at this stage. The stack that lets you ship in six weeks is not the same stack you will optimize at week twelve. Connecting these layers cleanly is where our system integration work pays off.
Step 5: Build the minimum pipeline. “Minimum” does not mean incomplete. It means instrumented. Every query logged, every response scored, every API call timestamped. A pipeline without observability is not a minimum viable system. It is a system you cannot improve.
✅ Steps 6 to 7: Evaluate Before You Ship
Step 6: Run a labeled evaluation. Before any user touches the system, run at least 100 real-world queries through it and score the outputs against a labeled baseline. Use RAGAS for RAG pipelines. This is not optional. Shipping without an eval baseline means the first user complaint is your baseline.
Step 7: Harden for production. Circuit breakers on all API calls (a circuit breaker stops an API loop if cost or error thresholds are exceeded). Hard spend caps. Alerting on token consumption. Tribal knowledge documentation: every module explained in writing by the engineer who built it. The system needs to survive an on-call incident at 2 AM when the senior engineer is not available.
⏰ Where Time Actually Goes
The ratio that surprises every client: the data schema and chunking work in step two consistently takes longer than the model integration in step five. The retrieval quality ceiling is set by the data layer, not the model.
A Teamvoy AI MVP engagement runs 6 to 10 weeks from first call to a production-grade system. One week for calibration and data audit, two weeks for architecture and pipeline, two weeks for the MVP build, one week for evaluation, and a final week for hardening and handover. The model is the last thing we discuss, not the first, because by the time we reach model selection, we already know what the data layer can support. If you want to test scope before committing, our proof of concept services ship a meaningful first milestone, not a finished product.
“Teamvoy remained a great partner of the client for four years and their work has been an essential part of the client’s growth. Having a great workflow, they communicated daily with the client’s globally dispersed team.”
George Harrap, CEO, Bitspark Teamvoy Clutch Verified Review
Q5: What Tech Stack Does a Production-Ready AI MVP Actually Need in 2026?
Most founders I talk to pick their AI stack the same way they pick their model: before they understand what the system actually needs to do. The result is a clever stack that cannot be debugged at 2 AM and a rewrite nobody budgeted for.
A production-ready AI MVP needs five specific layers. Getting them right once is cheaper than rebuilding them after launch. This is the foundation of our AI development services.
⭐ The Five Non-Negotiable Layers
| Layer | Recommended Tool | Open-Source Alternative | Use the Alternative When | Why It Matters |
|---|---|---|---|---|
| Foundation Model API | GPT-4o Mini / Claude Haiku | Llama 3 70B via Groq | Data residency rules prohibit external APIs | The inference engine; everything else wraps it |
| Orchestration | LangChain or LlamaIndex | Custom lightweight runner | You have a simple single-step pipeline | Manages retrieval, prompt chaining, and tool calls |
| Vector Database | Pinecone (managed) | pgvector (if on Postgres) | You are already on Postgres | Stores and retrieves embeddings for RAG |
| Evaluation Framework | RAGAS | LLM-as-judge | You need custom domain scoring | Measures retrieval and generation quality automatically |
| Observability | Langfuse or Helicone | Custom logging | Budget is constrained at MVP stage | Logs every query, latency, cost, and failure |
At Teamvoy, stack selection is an output of the data audit, not an input to it. The tools above reflect what we reach for after understanding the system, not a preference list decided before we do. Where the system is already live, our IT audit services surface the constraints first.
⚠️ The Build vs. Buy Trap
Every custom integration you build to connect your AI system to an external data source becomes something you own forever. Every API schema change, every authentication rotation, and every custom field mapping is yours to maintain.
I have seen teams become full-time integration maintenance crews six months after launch. Build custom integrations only if you have a dedicated platform team and your core data systems are genuinely unique. Otherwise, use managed connectors and spend the engineering hours on the product layer. This is exactly the trade-off our system integration work is designed to navigate.
💸 Observability Is Not Optional
The team that ships without logging owns every future outage. Every query should produce a trace: what was retrieved, what was sent to the model, what the model returned, how long it took, and what it cost.
This data is not just for debugging. It is the dataset that tells you when to upgrade your model, when your retrieval quality is drifting, and whether your cost-per-query is scaling correctly with usage. The most expensive line item in an AI MVP is not the API bill. It is the rewrite you did not budget for because the orchestration layer gave you no signal before it failed. Our AI integration services build this signal in from the first sprint.
Q6: How Much Does an AI MVP Actually Cost, and What Is the Quadratic Billing Bomb?
A production-grade AI MVP (a RAG pipeline, a foundation model API, a vector database, and a minimal front end) typically costs $15,000 to $60,000 to build and $200 to $2,000 per month to run at modest usage. The number that surprises founders is not the build cost. It is what happens to inference costs when you add agent loops. Our AI integration cost guide walks through these tiers in detail.
💰 Build Cost Breakdown
| Cost Component | Basic MVP | Intermediate MVP | Agent-Based MVP |
|---|---|---|---|
| Development labor | $8,000 to $15,000 | $18,000 to $30,000 | $30,000 to $55,000 |
| Model integration | $1,000 to $2,000 | $2,000 to $4,000 | $4,000 to $8,000 |
| Vector DB setup | $500 to $1,500 | $1,500 to $3,000 | $2,000 to $4,000 |
| Embedding pipeline | $500 to $1,000 | $1,000 to $2,500 | $2,000 to $4,000 |
| Evaluation framework | $500 to $1,000 | $1,000 to $2,000 | $1,500 to $3,000 |
| Circuit breakers and hardening | $500 to $1,000 | $1,000 to $2,000 | $2,000 to $4,000 |
💸 Monthly Inference Costs at Scale
| Daily Queries | GPT-4o Mini | Claude 3 Haiku | Gemini 1.5 Flash |
|---|---|---|---|
| 1,000 | ~$1/mo | ~$2/mo | ~$0.50/mo |
| 10,000 | ~$11/mo | ~$18/mo | ~$4/mo |
| 100,000 | ~$108/mo | ~$180/mo | ~$38/mo |
These are inference-only figures. Add vector database hosting ($70 to $300 per month for Pinecone Starter to Standard), embedding generation ($1 to $10 per month at these volumes), and observability tooling ($0 to $50 per month), and the real total cost of ownership is 30 to 60% higher than the model bill alone. Keeping that number in check is the focus of our IT cost optimization work.
❌ The Open-Source Crossover Point
Self-hosting Llama 3 70B on a dedicated A100 GPU (via a cloud provider) costs roughly $2 to $3 per hour, or $1,500 to $2,200 per month for continuous operation. At 10,000 daily queries, closed APIs win on cost. At 100,000 daily queries, the crossover point arrives. Self-hosting becomes cost-competitive at sustained high volume, but it adds operational overhead most MVP teams cannot absorb in the first six months.
⚠️ The Quadratic Billing Bomb
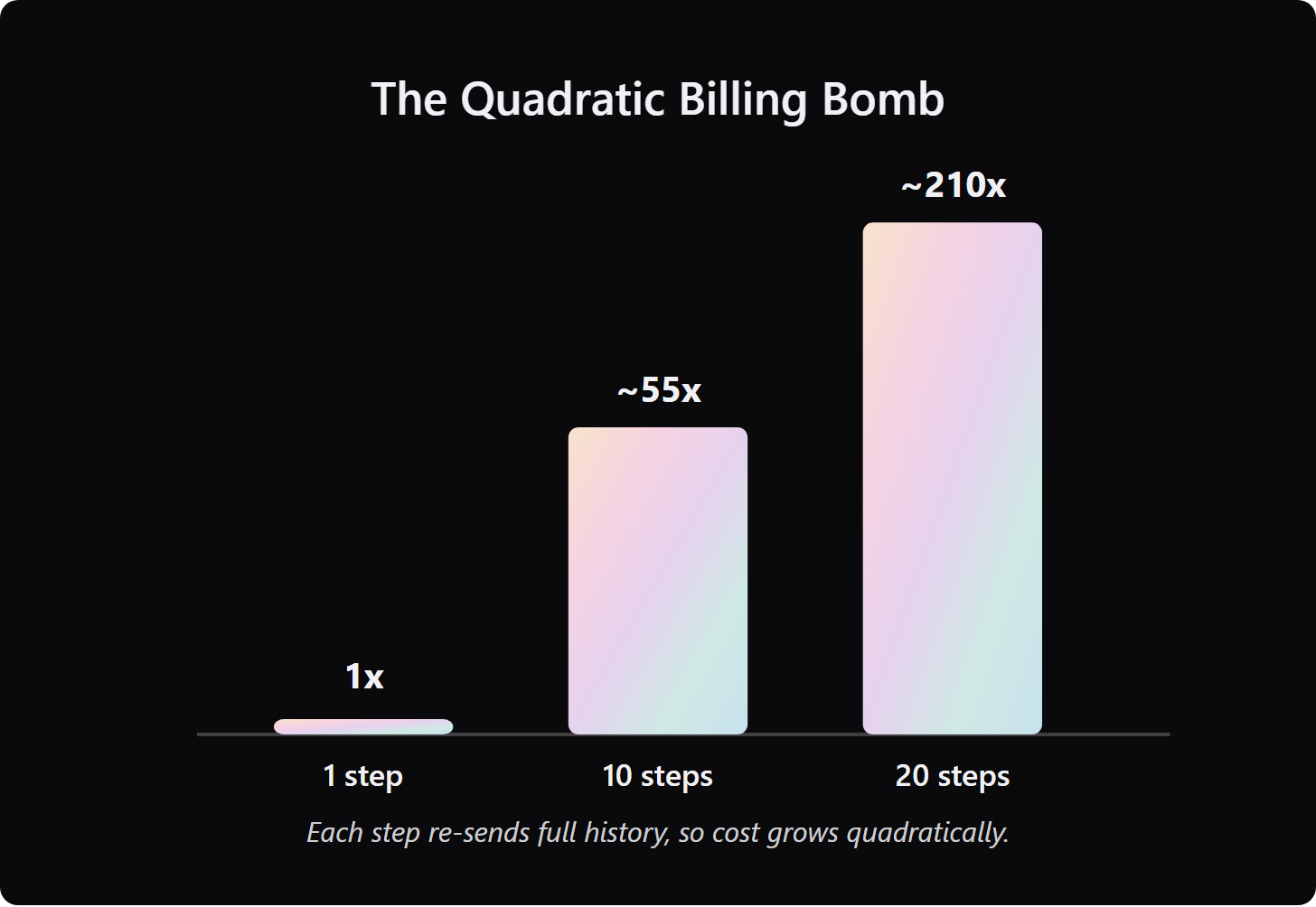
LLM APIs are stateless. They have no memory between calls. When an agent framework runs a multi-step task, it re-sends the entire conversation history on every step, appending each new tool call, error message, and intermediate result to the growing log.
A 10-step agent loop does not cost 10x one step. It costs roughly 55x one step (the sum of 1+2+3…+10 times the token price). A 20-step loop costs roughly 210x. That is the quadratic growth pattern.
One developer deployed a customer support agent that entered an infinite retry loop with a CRM integration. No circuit breaker existed. The agent ran for six hours while the developer slept and generated $4,200 in API charges before anyone noticed.
The $4,200 incident is not a story about a careless developer. It is a story about a missing architecture pattern. Every agent loop we build at Teamvoy carries a hard token cap, a retry limit, and an alerting threshold. Those three controls are built before the happy path, not after. This discipline is central to our AI agent development services.
“Teamvoy’s support and expertise have been integral in helping the client build and scale their product. An agile partner, they manage their tasks well and are consistent in delivering according to schedule.”
Gordon Little, Managing Director, Iress Teamvoy Clutch Verified Review
Q7: How Do You Know If Your AI MVP Is Working? Evaluation Metrics That Actually Matter
A senior engineer once showed me a demo of their AI document assistant. It answered every question in the demo perfectly. Three weeks after launch, users were quietly switching back to ctrl+F. The system looked right. It was not right. There was no evaluation baseline to catch the gap before it shipped.
Shipping an AI MVP without an evaluation framework is like launching a payments API without a test suite. The demo passes. The edge cases do not. This is one of the first things we test in our AI consulting engagements.
⭐ The Four Metrics That Matter
Retrieval precision: Of the chunks retrieved from your vector database, what percentage are actually relevant to the query? If your retrieval layer is returning noise, the model has nothing useful to work with.
Answer faithfulness: Is the model’s response grounded in the retrieved context, or is it generating from its training data? High faithfulness means the answer is traceable. Low faithfulness means the model is hallucinating.
Answer relevance: Does the response actually answer the question asked? A faithful answer can still miss the point.
Cost per correct answer: Total API and infrastructure cost divided by verified correct answers. This converts an abstract quality discussion into a number the business can evaluate.
RAGAS (Retrieval Augmented Generation Assessment), an open-source evaluation framework, automates scoring for the first three metrics. Cost per correct answer is a manual calculation, but it is the one number that changes how a CTO thinks about the build. Solid data engineering is what makes these metrics measurable in the first place.
⚠️ Why “Almost Right” Is the Expensive Problem
AI-generated pull requests contain an average of 10.8 issues, nearly double the 6.4 found in human-written code. The dangerous ones are not the obvious failures.
A completely wrong answer fails immediately. Tests break. The build stops. Someone fixes it.
An almost-right answer passes code review. It ships. It sits in the codebase for six months while users experience subtle degradation. By the time the problem surfaces, the cost to trace and fix it has compounded into something nobody budgeted for. We cover this dynamic in our analysis of vibe coding security risks.
✅ How We Run Evaluations at Teamvoy
Before any AI feature ships from a Teamvoy engagement, we run a minimum 100-query labeled evaluation. Queries are drawn from real user scenarios, not synthetic examples. Each answer is scored against the four metrics. The results either clear the threshold or trigger a debugging cycle before launch.
One useful edge-case technique: before launching a migration or major feature, generate a comprehensive manual test checklist using the AI itself. A well-prompted agent will produce 100 to 150 specific test cases, including account merging edge cases, permission boundary conditions, and data integrity scenarios that a human-written test list would miss.
If your MVP does not have an evaluation baseline yet, that is where the conversation starts, not a proposal, just a calibration against real queries. You can begin that conversation through our contact page.
“Teamvoy have been an integral part of the project throughout our journey. Their team helped us create a proof of concept and minimum viable product, then helped us build a talented team and bring the product to scale for 2 years.”
Gordon Little, Managing Director, Iress Teamvoy Clutch Verified Review
Q8: What Are the Compliance and Data Residency Risks Most AI MVPs Ignore?
An enterprise IT director I worked with recently described a specific moment: the legal team asked where user data went when it was sent to the AI assistant. Nobody in the room knew. The vendor had been live for four months.
That is not an unusual story. Most AI MVP guides skip compliance entirely. The assumption is that compliance is a production concern, not an MVP concern. That assumption is expensive to hold, especially in regulated banking and fintech environments.
⚠️ Every API Call Is a Data Transfer
Every call to an external foundation model API routes user input, context, and potentially personal data through a third-party processor. If your users are in the EU, GDPR Articles 44 to 46 govern that transfer. Standard contractual clauses (SCCs) and data processing agreements (DPAs) must be in place before the first production query.
OpenAI, Anthropic, and Google each publish DPAs and SCCs. Most founders have not signed them. Most enterprise procurement teams will block deployment when they discover that.
❌ The HIPAA and PHI Problem
HIPAA (the Health Insurance Portability and Accountability Act) requires a signed Business Associate Agreement (BAA) with any vendor that processes Protected Health Information (PHI). Most foundation model providers do not sign BAAs by default.
OpenAI offers a HIPAA-eligible configuration through Azure OpenAI Service. Google offers similar coverage through Vertex AI. The default consumer API endpoints are not HIPAA-eligible. If you are building a healthcare AI MVP and you are hitting the standard API endpoint, you have a compliance problem regardless of what the demo shows.
⭐ The EU AI Act Tier You Need to Know
The EU AI Act (Regulation 2024/1689), which came into force in August 2024, classifies AI systems by risk tier. High-risk classifications include AI systems used in employment decisions, credit scoring, medical devices, and critical infrastructure. If your MVP touches any of those domains, you have documentation, human oversight, and transparency obligations before you ship to EU users. We cover this groundwork in our guide on building regulator-ready AI in fintech.
✅ The Open-Source Compliance Argument
One legitimate architectural reason to self-host an open-source model: data never leaves your infrastructure. For HIPAA workloads where no BAA is available, or for financial services firms with data sovereignty rules under DORA or PCI-DSS, self-hosting Llama 3 or Mistral on a private cloud instance is not a cost decision. It is a compliance decision. For insurance carriers with legacy data estates, this trade-off comes up often.
The operational overhead is real. You own the model updates, the hardware provisioning, and the security patching. That trade-off is worth making when the alternative is a regulatory breach.
Across every AI engagement at Teamvoy involving healthcare, EU user bases, or regulated financial services, the compliance question is on the intake form, not the launch checklist. We have configured Azure OpenAI Service for HIPAA-eligible workloads, set up EU data residency on Vertex AI, and built DORA-aligned audit trails for AI systems in financial services. It is not exotic work. It is just work that has to happen before the first user query, not after. Our IT audit services map these data flows before any code is written.
Q9: What Are the Five Most Expensive AI MVP Mistakes, and How Do You Avoid Them?
The five most expensive AI MVP mistakes are: building agent loops without circuit breakers, deploying without an evaluation baseline, dumping unstructured data into a vector database and calling it RAG, treating access controls as an afterthought, and shipping AI-generated code nobody on your team can maintain. Each one is recoverable. None of them are cheap to recover from. The recovery almost always costs more than the original build.
I have been called in after all five of these, sometimes in the same system. The order varies. The cost structure does not. This is the core of our technology modernization work.
❌ Mistake 1: No Circuit Breaker on Agent Loops
An agent loop (a sequence where the AI calls tools, reads results, and calls tools again) is stateless. Every step re-sends the full history. A loop with no token cap or retry limit does not fail cleanly. It runs until your credit card does.
One developer deployed a customer support agent that hit an infinite retry loop with a CRM integration. No circuit breaker. Six hours, $4,200 in API charges, and one very uncomfortable morning. This is why our AI agent development services build hard limits before anything else.
❌ Mistake 2: No Evaluation Baseline Before Launch
The almost-right answer is more expensive than the completely wrong one. A completely wrong answer breaks tests and gets caught. An almost-right answer ships, sits in production, and compounds for six months before anyone traces it back to the retrieval layer.
AI-generated pull requests average 10.8 issues per PR, nearly double the 6.4 found in human-written code. Shipping without a labeled evaluation baseline means your first user complaint is your quality signal. That is too late.
❌ Mistake 3: Dumb RAG Architecture
Dumb RAG means dumping your entire Confluence history, Slack archive, and Salesforce export into a vector database (a database that stores text as searchable numeric embeddings) and expecting the model to find the right answer. It does not. The context window fills, accuracy degrades past the 40% threshold, and the model returns plausible-sounding noise instead of grounded answers.
The fix is not a bigger model. It is chunking strategy, metadata filtering, and a re-ranking layer before you ever touch the API. Getting the underlying data engineering right is what separates working RAG from Dumb RAG.
⚠️ Mistake 4: Security as an Afterthought
A review of 5,000 AI-built applications found that 60% had significant security vulnerabilities, including missing authentication controls and exposed data endpoints. One founder discovered, mid-demo to an investor, that any user could query anyone else’s records. It was not a bug. It was a missing access control layer that nobody had thought to add.
Vibe-coded apps (applications assembled primarily using AI tools like Cursor IDE or Replit) often reach a working demo without anyone asking, “Who should not be able to see this?” We unpack this pattern in our analysis of vibe coding security risks.
❌ Mistake 5: Tribal Knowledge Failure
An on-call engineer hit a production incident at 2 AM. The AI suggested restarting the server. He restarted it six times. By the time the senior engineer was escalated to, she looked at the logs for thirty seconds and diagnosed a full database connection pool. She knew in thirty seconds because she had built that part of the system.
That knowledge was not documented anywhere. That is the mistake. Recovering systems like this is the focus of our guide on updating systems nobody understands.
✅ Pre-Launch Checklist (Run This Before Shipping)
- Circuit breaker implemented on every agent loop
- Hard spend cap set on the API account
- Evaluation baseline established with at least 100 labeled queries
- Data flow diagram exists and is current
- Access controls scoped and tested per user role
- Every module in the codebase can be explained by at least one engineer on the team
- Tribal knowledge documented: failure modes, restart procedures, and known edge cases
If you are not sure whether your AI MVP clears this list, Teamvoy offers a 3 to 5 day AI and System Readiness Audit, a structured technical review with a written output you own, no proposal, no sales process. You can request it through our contact page or see the standards we hold in our IT audit services.
“Teamvoy actively uses agentic AI across internal workflows and delivery, which speeds up development, raises quality, and adds extra value for the client.”
Manager, Takflix Teamvoy Clutch Verified Review
Q10: How Does Teamvoy Approach AI MVP Development, and What Does a Typical Engagement Look Like?
Teamvoy does not start an AI MVP engagement with model selection. We start with the data layer, the accuracy baseline, and the architecture that has to survive production. A typical engagement runs 6 to 10 weeks from first call to a production-grade system: one week for calibration, two weeks for architecture and data pipeline, two weeks for the MVP build, one week for evaluation, and a final week for hardening and handover. The model is the last decision, not the first. This is the spine of our AI development services.
⭐ The Clients We Work With
The first scenario: a CTO who inherited an AI pilot that cost $40,000, ran for three months, and returned hallucinated answers nobody caught until a client escalated. The demo worked. Production did not. The data layer was never audited before the model integration started.
The second scenario: a founder who built fast with Cursor IDE and freelancers. The product has real users. The system has no observability, no circuit breakers, and no person on the team who can explain the retrieval logic. It works until it does not, and when it does not, nobody knows where to look.
The third scenario: a Technical Founder adding AI to a system already under three years of accumulated decisions and patches. The system has to keep running during the integration. A rewrite is not an option. The data is partially structured, partially not, and nobody has mapped it. Our AI integration services are built for exactly this situation.
⚠️ What They Tried Before Calling Us
In most cases, they started at step three: model selection. They picked GPT-4o because it was the most capable option. They skipped the data audit because it felt like pre-work, not real work. They shipped without evaluation because the demo looked right.
The pattern I have seen repeat across twelve years of delivery: the questions that feel like slowing down are the ones that prevent the $40,000 rebuild. The data audit takes a week. The rewrite it prevents takes four months. We cover why this happens in our piece on the tech debt avalanche.
✅ How a Teamvoy AI Engagement Actually Runs
| Week | Work |
|---|---|
| Week 1 | Calibration: measure the accuracy baseline, map the data layer, and define the success metric |
| Weeks 2 to 3 | Architecture decision and data pipeline: chunking, embedding, and retrieval design |
| Weeks 4 to 5 | MVP build: minimum pipeline, fully instrumented, with observability from day one |
| Week 6 | Labeled evaluation: 100+ real queries scored against RAGAS metrics |
| Week 7+ | Hardening: circuit breakers, spend caps, documentation, and handover |
A senior engineer takes ownership of the system, end to end, with an AI-native team behind them. This is the opposite of a handoff model where junior engineers rotate through and nobody owns the outcome. You can see how this plays out in our case studies.
💰 What the Engagement Produces
At the end of a Teamvoy AI MVP engagement, you have a production-grade system, a labeled evaluation baseline, documented failure modes, and a senior engineer who can explain every decision that was made and why. You also have a clear picture of what the next milestone requires, and whether the architecture you have will support it.
“Teamvoy have been an integral part of the project throughout our journey. Their team helped us create a proof of concept and minimum viable product, then helped us build a talented team and bring the product to scale for 2 years. I have fully relied on Teamvoy’s technical decisions and it worked well.”
Gordon Little, Managing Director, Iress Teamvoy Clutch Verified Review
“Teamvoy has successfully launched the system within the set timeline and integrated all the required tools and features. Their proactive problem-solving approach and commitment to innovation stand out.”
Anonymous, COO, Marketing Company Teamvoy Clutch Verified Review
I started Teamvoy because I had watched too many projects fail for reasons that had nothing to do with the technology and everything to do with the questions nobody asked before the first line of code was written. That is still the job. You can read more about our team on our About Teamvoy page.
If you are at a decision point, whether it is RAG or fine-tune, which API, how much this will actually cost, or whether your existing AI system has the architecture it needs to survive production, that is the conversation we are built for. Tell us what you are building. We will tell you which question to answer first. Our proof of concept services are often where that first milestone takes shape.


